
Redis实战篇
Redis实战篇
在此感谢黑马程序员的相关课程
1 概述
该部分主要结合以下内容进行redis实现
- 短信登录
- Redis的共享session应用
- 商户查询缓存
- 企业的缓存使用技巧,缓存雪崩,穿透等问题的解决
- 优惠券秒杀
- Redis计数器,Lua脚本Redis,分布式锁,Redis的三种消息队列
- 达人探店
- 基于List的点赞列表
- 基于SortedSet的点赞排行榜
- 好友关注
- 基于Set集合的关注,取关,共同关注,消息推送等功能
- 附近商户
- Redis的GeoHash的应用,解决根据地理坐标进行搜索的功能
- 用户签到
- Redis的BitMap数据统计功能
- UV统计
- Redis的HyperLogLog的统计功能
准备:
1.导入SQL文件,其中包含的表有:
| 表名 | 用法 |
|---|---|
| tb_user | 用户表 |
| tb_user_info | 用户详情表 |
| tb_shop | 商户信息表 |
| tb_shop_type | 商户类型表 |
| tb_blog | 用户日记表(达人探店日记) |
| tb_follow | 用户关注表 |
| tb_voucher | 优惠券表 |
| tb_voucher_order | 优惠券的订单表 |
本次核心是Redis学习,因此项目没有采用微服务,防止java代码多,复杂
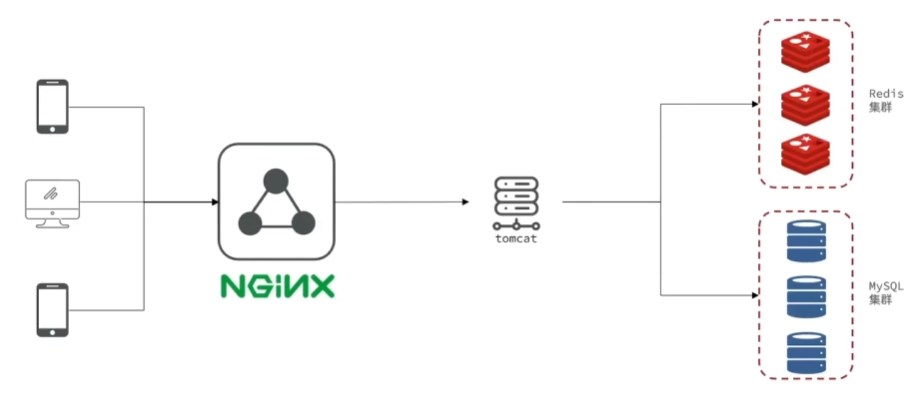
- 该项目是单体项目,但采用前后端分离模式
- 前端部署在nginx服务器上,后端部署在tomcat上
- 移动端或pc端向nginx发起请求,得到静态资源,页面再通过nginx向服务端(tomcat)发起请求查询数据(来自Redis集群或MySQL集群),返回给前端,最后渲染
- 考虑到项目的并发能力,项目应具有一定的水平扩展能力
- 项目部署在tomcat后,如果nginx-tomcat压力较大,允许进行水平扩展,形成负载均衡的集群,在多台tomcat上部署代码
- 部署集群后会出现集群间的数据共享的问题
- 项目部署在tomcat后,如果nginx-tomcat压力较大,允许进行水平扩展,形成负载均衡的集群,在多台tomcat上部署代码
项目架构图:
2.导入后端项目源码,进行二次开发
修改yaml文件的配置为自己的,jdk21的需要将lombok版本升到1.18.42(至少1.18.34)
访问http://localhost:8081/shop-type/list,可以看到数据证明运行没有问题
3.导入前端
- 在nginx文件打开命令终端,输入
start nginx.exe运行nginx,之后在上面的网页打开开发者页面,左上角进入手机模式,修改网页为http://local:8080显示图片说明前端导入成功。也可以直接打开
http://local:8080。
2.短信登录
2.1基于Session实现登录
2.1.1 发送短信验证码
基本流程如下:
用户提交手机号-><校验手机号->生成验证码->保存验证码到 session中->发送验证码
请求路径:http://localhost:8080/api/user/code?phone=18437347577
请求方式:post
短信发送需要第三方平台,但邮箱不用,因此我选择换成邮箱验证
- 导入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<!-- https://mvnrepository.com/artifact/javax.activation/activation -->
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/javax.mail/mail -->
<dependency>
<groupId>com.sun.mail</groupId>
<artifactId>jakarta.mail</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>com.sun.activation</groupId>
<artifactId>jakarta.activation</artifactId>
<version>2.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-email -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-email</artifactId>
<version>1.4</version>
</dependency>
创建一个工具类 MailUtils,实现邮箱的验证码发送
代码较长这里不再展示
1 | package com.hmdp.utils; |
获取验证码
实现验证和保存逻辑:
可以看到UserControllerd的成员方法userService是IUserService接口类,他的实现类是UserServicelmpl,可以令sencode方法调用并返回userService的sendcode方法,并在UserServiceImpl类中实现
- 完成service下的接口类IUserService的方法实现类IUserServiceImpl的sendcode方法
1 |
|
完成后重启服务,可以看到qq邮箱收到了验证码。
接下来实现短信验证码的的登录功能
2.1.2 短信验证码登录,注册
基本流程如下:
提交手机号和验证码-><校验验证码,与保存的比较->根据手机号查询用户信息->用户存在->保存用户到session /用户不存在->创建新用户->保存用户到数据库
与上面验证验证码的流程大致相同,修改UserController的login方法
1
2
3
4
5
public Result login( LoginFormDTO loginForm, HttpSession session){
// 实现登录功能
return userService.login(loginForm,session);
}完成UserServiceImpl中的login方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
public Result sendCode( String phone, HttpSession session) throws MessagingException {
// 发送短信验证码并保存验证码
if (RegexUtils.isEmailInvalid(phone)) {
return Result.fail("邮箱格式不正确");
}
String code = MailUtils.achieveCode();
session.setAttribute(phone, code);
log.info("发送登录验证码:{}", code);
MailUtils.sendTestMail(phone, code);
return Result.ok();
}
public Result login(LoginFormDTO loginForm, HttpSession session) {
//获取邮箱
String phone = loginForm.getPhone();
//校验 //已处理 此处BUG,需要处理是否与之前存的phone相同 ,可以考虑将phone作为session id
if (RegexUtils.isEmailInvalid(phone)) {
return Result.fail("邮箱格式不正确");
}
//校验验证码
Object cacheCode = session.getAttribute(phone);
String code = loginForm.getCode(); //前端提交的code
//日志记录
log.info("code:{},cacheCode{}", code, cacheCode);
//不一致
if(cacheCode==null||!cacheCode.toString().equals(code)){
return Result.fail("验证码错误!");
}
//查询用户是否已存 Mybatisplus
//本类继承了由Mybatisplus提供的ServiceImpl,用以实现单表的增删改查因此可以使用query
//User user = query().eq("phone", phone).one();
//建议使用LambdaQueryWrapper
//5. 根据账号查询用户是否存在
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getPhone, phone);
User user = getOne(queryWrapper);
//不存在 :注册,创建并保存用户到数据库
if(user==null){
user=creatUSerWithPhone(phone);
}
//登录,保存到session
session.setAttribute("user",user);
return Result.ok();
}
//创建用户
private User creatUSerWithPhone(String phone) {
User user = new User();
user.setPhone(phone);
user.setNickName(USER_NICK_NAME_PREFIX+RandomUtil.randomString(10));
//保存用户
save(user);
return user;
}还是建议多做日志记录用来处理错误信息的,比如上面代码就是28行进行了前端code和session保存的cachecode的输出,才发现两次的值不一样,才找到错误改正代码的
2.1.3 校验登录状态
前言:
- session基于cookie,每一个session都有一个sessionID保存在浏览器的cookie当中
- 随着业务的开发,需要进行用户登录校验的业务会越来越多,为了避免在每一个Contorller类中都进行自己需求的校验实现,增强代码的可复用性,可以使用SpringMVC的
拦截器,用户的请求不再直接到Controller中,而是先经过拦截器判断是否放行 - 现在要考虑一个问题?如何将拦截器得到的信息发送到对应的对象,并确保线程的安全?
- 使用线程域对象
Threadlocal: 每一个进入Tomcat的请求都是独立的线程,threadlocal 会在线程内开辟一块内存空间来保存用户信息,请求到达对象后其在Threadlocal内取信息即可
- 使用线程域对象
基本流程如下:
用户请求登录并携带cookie->从sessiom获取用户->判断是否存在->保存用户到Threadlocal中,便于后续调用用户信息
实现:
- 创建LoginInterceptor类,重写实现HandlerInterceptor接口的两个方法preHandle和aftercompletion,分别用于
信息校验和最后的信息处理,销毁,防止内存泄漏
1 | public class LoginInterceptor implements HandlerInterceptor { |
工具包Util里已经实现了UserHolder类
因此15行必须强转成UserDTO,至于为什么使用UserDTO会在下面解释
1 | public class UserHolder { |
创建 MvcConfig类配置Treadlocal使其生效,最后在登录验证时调用即可
1 |
|
最后,完善me方法,用以返回给前端数据
1 |
|
- 我们初始化user对象时,idea将其自动初始化成了UserDTO对象,为什么使用了UserDTO而不是User?
我们在在浏览器开发者工具可以看到,返回到前端的信息包含了所有用户信息,不仅泄漏了敏感信息,还增大了内存负担
我们可以使用UserDTO对象,只传递部分信息,项目dto包内已经有了lUserDTO类,将UserServiceImpl类中login方法内session改成从UserDTO获取
1 | //登录,保存到session |
2.2 基于Redis解决session共享问题
使用Session登录又一个很大的问题就是:
- 集群的session共享问题: 多台Tomcat并不共享session空间,当请求切换到不同Tomcat时会数据丢失。
- 早期的一个解决方法是数据拷贝,即session数据更新时向所有Tomcat服务器拷贝更新一份数据,这样所有Tomcat都会有session信息,但是这样有很大的弊端:
- Tomcat内存压力大
- 数据拷贝有
- 早期的一个解决方法是数据拷贝,即session数据更新时向所有Tomcat服务器拷贝更新一份数据,这样所有Tomcat都会有session信息,但是这样有很大的弊端:
- 需要有一个可以替换session的方法,且必须满足:
- 能够实现数据共享
- 使用内存储存
- 满足key,value结构
- 没错,终于可以使用刚认识的Redis了,
- redis是键值型数据库,但它的Value有很多种类,由于目前我们要储存的数据结构简单,因此可以选择string或hash类型
- string序列化为Json格式,更直观
- hash将字段独立存储,更容易CRUD,同时使用内存较小
- 虽然我们目前的数据存储对内存需求不大,同时一般不会对这里的用户数据做增删改查,但基于优化角度,还是选择hash较好
- 接下来选择key
- session的一大特点是每一个浏览器在发请求时都有一个独立的session,Tomcat会维护不同的session,但redis是共享的内存空间,使用之前的code作为key会覆盖,出现问题,因此必须使用具有唯一性的标识当key,而容易想到的手机号属于敏感信息,应该使用随机token
- 登录时,我们需要额外手动把这个token返回到客户端(浏览器),这样当其发送请求时可以携带这个token做标识。
- 接下来修改之前的保存用户信息的代码:
1.注入StringRedisTemplate并修改login方法:
1 | + |
2.RedisContants类来规范控制常量的输入:
1 | public class RedisConstants { |
3.修改login方法:
1 |
|
关于用户存活周期,所有请求都要经过拦截器的拦截和校验,可以借此使用拦截器来判断用户是否仍在活跃,进而决定是否更新Redis有效期:
- 修改LoginInterceptor类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37private StringRedisTemplate stringRedisTemplate;
public LoginInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// //获取session
// HttpSession session = request.getSession();
//获取token
String token = request.getHeader("authorization");
// //获取用户信息
// Object user = session.getAttribute("user");
//基于token获取Redis中的用户
if (StrUtil.isBlank(token)) {
response.setStatus(401); //未授权
return false;
}
String key = RedisConstants.LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(key);
//不存在,拦截
if (userMap.isEmpty()) {
response.setStatus(401); //未授权
return false;
}
//将查询到的Hash数据转为USerDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
//存在,保存到ThreadLocal
UserHolder.saveUser(userDTO);
//刷新token有效期
stringRedisTemplate.expire(key,RedisConstants.LOGIN_USER_TTL, TimeUnit.MINUTES);
//放行
return true;
}
这里不能使用注解注入StringTemplate,只能使用构造函数注入,因为LoginInterceptor类的对象是我们手动new出来的,不是通过spring注解构建的,想要注入可以在使用了这个对象的地方注入,即MvcConfg中,MvcConfig使用了@Configuration,由Spring构建,可以进行依赖注入,因此需要修改:
1 |
|
现在登录后会发现开发者工具me的请求登录项有了authorization,这就是token值,同时,打开RESP也能看到有了Login的Hash结构。
2.3 登录拦截器的优化
上面我们使用Redis替代session时,利用了拦截器来刷新用户状态,但是我们的拦截器只会在Control类作用,也就是说只有在进行登录注册等操作时才会刷新状态,而其他业务如查看商铺信息,首页等不需要拦截器的操作则不会,如果用户一直不进行使用拦截器的操作,即使在访问信息也会因失效而退出,这是不合理的需要优化。
- 水多加面,再加一个拦截器,拦截一切路径,获取token,查询Redis用户,存在则保存到Threadlocal并刷新,最后放行,查询不存在也不做处理,放行
- 而之前的拦截器则不需要重复完成获取查询操作,仅需要再Threadlocal查询用户,完成拦截
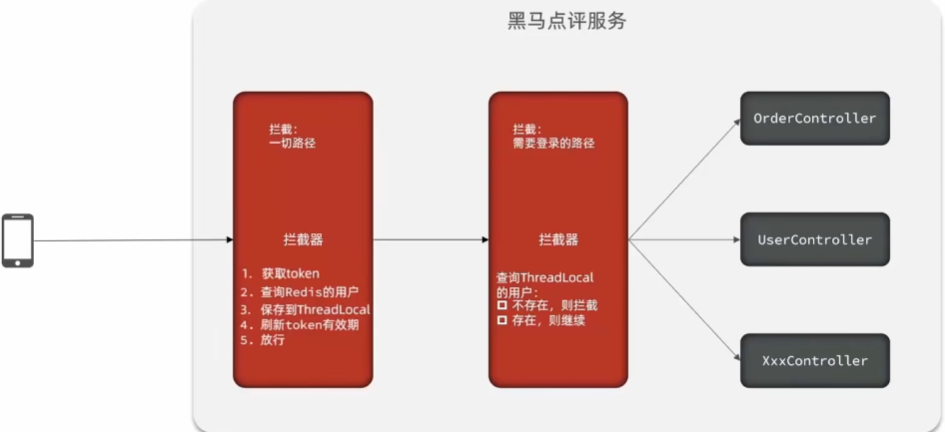
添加
RefreshTokenInterceptor类,与LoginInterceptor除了判断为空时return true外,其它代码一样,然后修改LoginInterceptor和MvcConfig:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class LoginInterceptor implements HandlerInterceptor {
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//根据ThreadLocal中是否有用户信息判断是否放行
if(UserHolder.getUser()==null){
//拦截
response.setStatus(401);
return false;
}
//放行
return true;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class MvcConfig implements WebMvcConfigurer {
private StringRedisTemplate stringRedisTemplate;
public void addInterceptors(InterceptorRegistry registry) {
//放行不需要拦截的路径
registry.addInterceptor(new LoginInterceptor()).excludePathPatterns(
"/user/code",
"/user/login",
"/blog/hot",
"/shop/",
"/shop-type/",
"/upload/",
"/voucher/"
).order(1);
//token刷新的拦截器
//order控制执行顺序更高,addPathPatterns确保判断所有请求
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate))
.addPathPatterns("/").order(0);
}
}最后重启服务,在前端页面登录后,执行刷新操作(刷新时执行me业务)或其他操作,会发现RESP的前后TTL不同了,刷新后比之前大,这说明拦截器逻辑成功执行。
3 商户查询缓存
3.1 店铺信息与商户类型的缓存
- 缓存:数据交换的缓冲区(cache),是贮存数据的地方,一般读写性能较高,
- 添加Redis缓存相当于在客户端与数据库之间加入了Redis做中间件,Redis未查到再向数据库查询,这样能够极大缓解数据库压力
在 ShopController中调用IShopService对象shopService的queryById方法,把业务放到Service中去做
1 |
|
在 IShopService中创建方法
1 | public interface IShopService extends IService<Shop> { |
找到实现类 ShopServiceImpl并实现方法
1 |
|
重启服务并在商铺页面刷新,在开发者工具可以找到商铺信息,并且可以发现,第一次刷新查询时间接近1000ms,再次刷新后却不到100ms,这就是利用了Redis缓存的结果
- 完成商户类型的数据缓存
与上面差不多
- 修改
ShopTypeController的queryTypeList方法1
2
3
4
5
public Result queryTypeList() {
//查询店铺类型
return typeService.queryTypeList();
} - 在
IShopTypeService接口创建方法 - 在
ShopTypeServiceImpl实现类中实现方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public Result queryTypeList() {
//从Redis缓存中查询商铺 //不为空一直查
List<String> shopTypes = stringRedisTemplate.opsForList().range(CACHE_SHOP_TYPE_KEY, 0, -1);
//商铺类型是ShopType,因此需要转换
//缓存中查到则转换并返回
if (!shopTypes.isEmpty()) {
//这里只用isEmpty()就行,这里会爆黄警告是因为idea貌似不知道range返回的不是null而是[],
List<ShopType> shopTypeList =new ArrayList<>();
for(String s:shopTypes){
ShopType shopType = JSONUtil.toBean(s, ShopType.class);
shopTypeList.add(shopType);
}
return Result.ok(shopTypeList);
}
//缓存中没有则查数据库
List<ShopType> typeList = typeService.query().orderByAsc("sort").list();
//数据库未查到
if (typeList == null) {
return Result.fail("未查询到店铺类型!");
}
//转为JSON字符串并键入shopTypes
for(ShopType s:typeList){
String jsonStr = JSONUtil.toJsonStr(s);
shopTypes.add(jsonStr);
}
//将更新的shopTypes存入Redis
stringRedisTemplate.opsForList().leftPushAll(CACHE_SHOP_TYPE_KEY,shopTypes);
return Result.ok(typeList);
}
完成后查询发现商品类型倒序展现了这是因为我们用了leftPushAll,新数据放在了表头,这恰好证明了缓存保存成功,刷新两次发现查询速度显著提高。
3.2 缓存更新策略
上面我们利用缓存实现数据高效查询时,忽略了一个问题,就是如何保证数据的统一性?比如我更新数据库信息后如何同步到Redis?内存中的旧数据如何清理?这就需要用到缓存更新策略
常用的策略有三种:
| 缓存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护, 利用Redis的内存让淘汰机制, 内存不足时自动淘汰数据, 查询时再更新 | 给缓存数据添加TTL时间, 到期后删除, 下次查询后更新缓存 | 编写业务逻辑, 更新数据库数据的同时同步更新缓存 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
业务场景:
- 低一致性需求:使用内存淘汰机制,比如商户类型
- 高一致性需求:主动更新+超时剔除
3.2.1 主动更新策略
逻辑实现有常用的三种模式:
- Cache Aside Pattern:人工编码方式,由缓存的调用者,在更新数据库时同步更新缓存
- Redis/Write Through Pattern:缓存与数据库整合成一个服务,由服务来维护统一性,调用者调用该服务,无需担心一致性问题
- Write Behing Caching Pattern 写回:调用者只操作缓存,由其他线程异步的将缓存数据持久化到数据库,保证最终一致性
其中方案二的服务成本高,方案三需要异步线程实时监测数据更新,并且实现复杂,此外缓存宕机会导致丢失数据
方案一虽然需要手动完成业务逻辑,但可控性高且比较稳定,通常选择方案一
接下来考虑操作时的问题:
- 更新还是删除缓存?
- 更新缓存:每次数据库数据更新都更新一次缓存
- 删除缓存:更新数据库时令缓存失效,查询时再更新缓存
- 如果选择更新缓存,那么对于同一份数据的每一次更新,缓存都要同步一次,不管有没有查询,这样无效的写操作会较多,而删除缓存是一种懒处理,只在查询时才同步到缓存
- 如何保证数据库与缓存操作的同时成功或失败呢?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
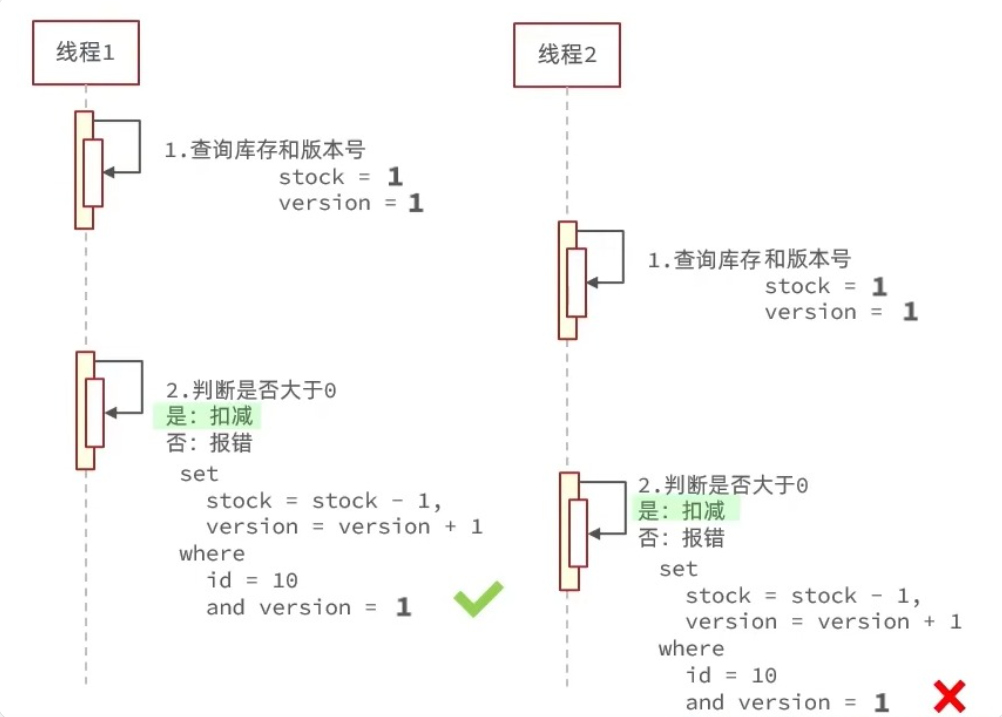
- 先操作缓存还是数据库?
- 这里主要是线程的安全问题
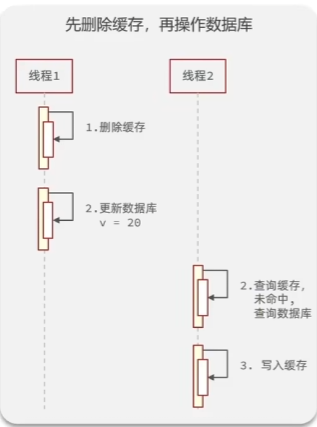
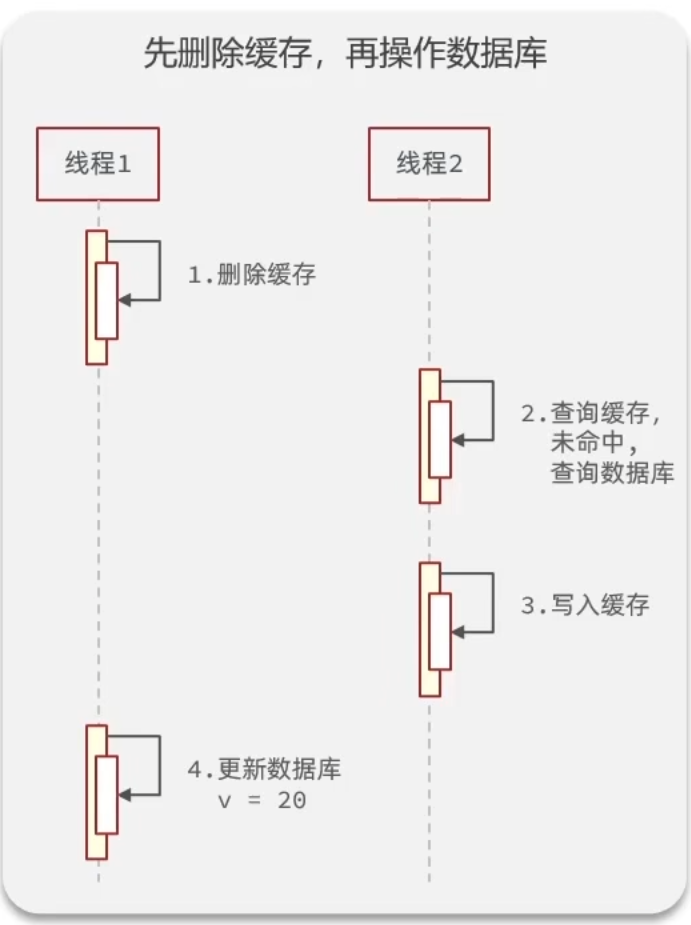
- 先删除缓存,再操作数据库
正常情况的并发线程流程应如图:
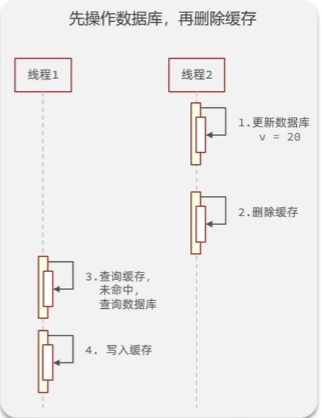
而异常情况下,会发生线程1删除缓存到未更新数据库的时间里,线程2查询缓存,未命中转到数据库查询,但此时线程1还未完成更新,从而获得了旧数据并写入了缓存的情况,这会导致缓存和数据库的数据不一致 - 先操作数据库,再删除缓存
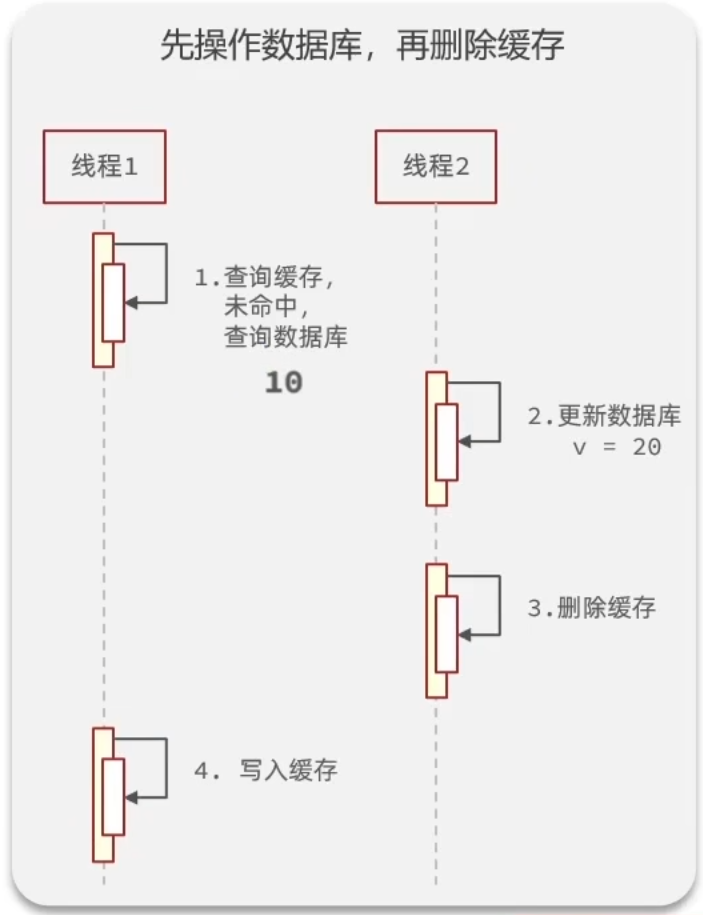
正常情况:
异常情况:缓存失效的时候会出现:在线程1查询缓存未命中,查询得到数据库数据后,另一个线程2更新了数据并删除了缓存,这之后线程1才将旧数据数据写入缓存,这种情况理论上发生的可能性比上一种小很多,应为缓存操作远快于数据库操作,但仍有概率发生,是不能忽视的线程安全问题
3.2.2 完善查询商铺缓存的策略
3.2.2.1 为查询商铺的缓存添加超时剔除和主动更新策略
根据id查询电普时,如果缓存未命中,则查询数据库,将数据库信息同步到缓存,并设置超时时间
前面已经完成了queryById方法,这里只需要在写入Redis时加上TTL即可1
2
3//查到数据,写入redis
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);根据id修改店铺时,先修改数据库,再删除缓存
修改ShopController的updateShop方法,在service层完成业务逻辑1
2
3
4
5
public Result updateShop( Shop shop) {
// 写入数据库
return shopService.update(shop);
}创建方法
1
2
3
4
5public interface IShopService extends IService<Shop> {
Result queryById(Long id);
Result update(Shop shop);
}完成实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public Result update(Shop shop) {
Long id = shop.getId();
if (id==null) {
return Result.fail("店铺id为空!");
}
//更新数据库
updateById(shop);
//删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
return Result.ok();
}
最后重启服务器,查询一个商铺,使其存入Redis缓存,之后利用POSTMAN发送PUT请求,路径为 http://localhost:8080/api/shop/携带修改过后的JSON数据,将name改为103茶餐厅
1 | { |
刷新网页,可以发现name已经修改成了113茶餐厅,并且Redis数据重载后也成功同步成113茶餐厅
3.3 缓存穿透
缓存穿透:客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库- 缓存穿透会引发严重的性能问题,例如:用户查询一个缓存和数据库都不存在的数据,返回的是空,接下来恶意使用多个线程并发地重复发送该请求,导致这些无效请求全部发到数据库,严重影响服务器性能。
目前常用的解决方案有两种:
- 缓存空对象:在缓存和数据库未查到数据后,将空值缓存到Redis,令后续请求在Redis中命中,不再继续向数据库请求
- 优点是简单暴力,维护也方便
- 缺点就是有额外内存消耗,并且可能导致数据短期的不一致,这些可以在缓存空值时加TTL缓解
- 布隆过滤:在客户端与Redis间插入布隆过滤器,请求先经过布隆过滤,不存在直接拦截,存在则放行到Redis进行后续查询
布隆过滤器不会存储所有数据,可以把它当做一个bit数组,存储的实际上是二级制位,它会基于哈希算法计算出数据的哈希值,并将该值转换为二进制位保存到b布隆过滤器中,判断是否存在时会判断该位是0/1- 这种判断实际上是一种概率的统计,由于使用了哈希思想,会存在哈希冲突,即布隆过滤器判断数据不存在就一定不存在,布隆过滤器判断的存在可能不准确(数据的二级制位可能被其他数据占用)
- 优点:内存占用小,没有多余的key
- 缺点:有误判率,实现复杂
3.3.1 缓存穿透的解决
- 在之前的代码逻辑中,我们令数据库中未查到数据后返回了404,这部分需要修改为返回空对象给Redis,并在判断缓存命中后判断是否空
修改queryById方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public Result queryById(Long id) {
//从Redis中查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
//查询到数据则返回
if(StrUtil.isNotBlank(shopJson)){
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
+ //到这里只可能是null或"" 判断是否为"",""需要直接返回,null则进继续查数据库
+ if(shopJson!=null){
+ return Result.fail("店铺不存在!");
+ }
//未查到则移交数据库查询并存入信息
//数据库未查到
Shop shop = getById(id);
if (shop == null) {
+ //Redis写入空值 解决缓存穿透
+ stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
return Result.fail("该店铺不存在!");
}
//查到数据,写入redis
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
}
重启服务器,开发者工具中新建标签页打开名称为1的请求,正常打印数据,将末地址1改为0,打印错误信息,证明成功执行了新增逻辑
3.3.2 小结
- 缓存穿透产生的主要原因是什么?
- 请求的数据在内存和数据库都不存在,连续发送同样的请求导致数据库压力过大
- 缓存穿透的解决方法有哪些?
- 数据库未查到返回空值给Redis
- 布隆过滤器
- 增加Id复杂度,避免恶意方得到Id规律,雪花算法
- 做好数据格式的基础校验
- 加强用户权限校验
- 做好热点参数的限流
3.4 缓存雪崩
- 缓存雪崩:同一时段的缓存中的大量key失效,或者Redis服务宕机,导致大量请求几乎同时到达数据库,给数据库带来巨大压力
- 解决方法:
- 赋予key的TTL随机性
- redis集群: 利用Redis哨兵实现服务的监控主节点宕机,哨兵从选取可用从节点替代主节点完成业务,确保Redis能够一直对外提供服务,为防止哨兵也宕机,也可以构建哨兵集群
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存:浏览器缓存(主要是静态数据);而动态数据可以访问反向代理服务器nginx层面的缓存;未命中再到redis查询;之后是JVM,可以在JVM内部建立本地缓存,最后去数据库
3.5 缓存击穿
缓存击穿问题又叫热点key问题,就是一个被高并发访问且缓存重建业务复杂的key突然失效,导致大量请求到达数据库
可以使用互斥锁或逻辑过期方法解决
互斥锁解决
其线程进程如下:
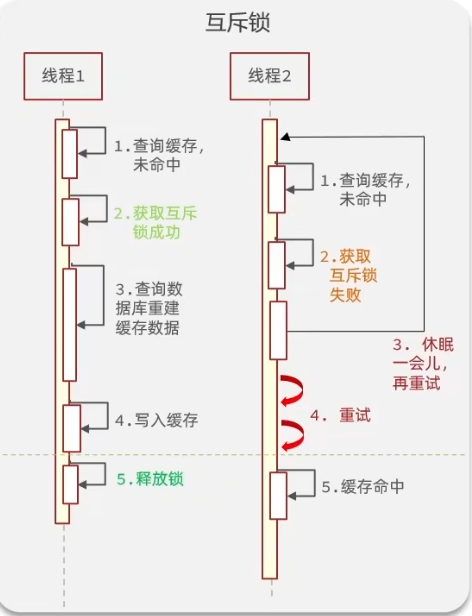
但使用互斥锁仍有不能解决的问题,主要有:
- 互斥锁会牺牲一定的性能
- 引起缓存击穿主要是因为为数据设置了TTL
结合以上两点,思考是否有一种方法,既不需要加锁牺牲性能,又可以解决TTL失效问题?
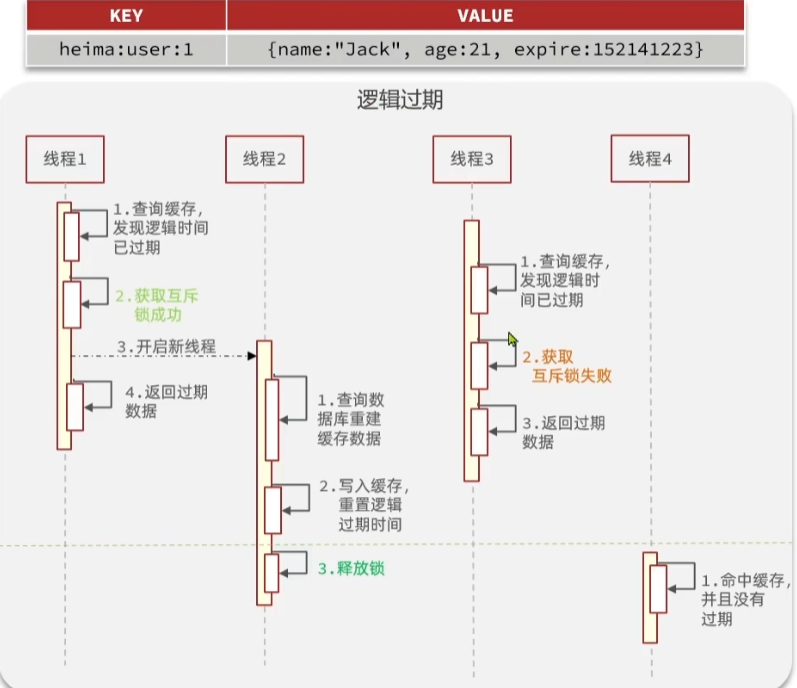
- 使用逻辑过期方法:数据存入缓存时不再设置TTL,而是使用在value添加逻辑过期时间的字段(通常为当前时间加上存在时间)这样就可以通过这个时间字段判断数据是否失效期,领数据在失效后也能够被查到,而不是直接删除。
- 具体是线程1查询缓存发现数据过期,成功获取互斥锁后开启新线程线程2,让线程2去更新数据,更新完成后释放锁
- 缺点很明显,在释放锁期间线程1和其他线程返回的都是旧数据(脏数据)
其存储方式及线程示例如下:
小结:
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外的内存消耗 保证一致性 实现简单 | 线程需要等待,会影响性能 可能有死锁风险 |
| 逻辑过期 | 无需等待,性能较好 | 一致性不能保证 有额外内存消耗 实现复杂 |
3.5.1 基于互斥锁解决缓存击穿问题
对于根据Id查询商铺的业务,缓存命中的情况无需修改,而缓存未命中的情况可以使用互斥锁解决缓存击穿问题
- 在缓存未命中后尝试获取互斥锁,拿到就重建数据,根据Id查询数据库,并写入Redis,最后释放锁,返回数据;没有则先休眠,一段时间后再查询缓存
- 需要注意的是,我们需要的这种互斥锁不同于常见的synchronized或lock锁,这些锁进程拿到就执行,拿不到就要一直等待, (并且他们是
单机锁,不能用于分布式),而我们期望的锁是逻辑自定义的,这就需要找到能实现类似互斥锁逻辑的方法 - 在Redis的数据结构中,String类型有这样一个命令:
SETNX,其作用是添加一个新的键对值,可以利用它实现类似互斥锁的功能
如上图所示,利用SETNX命令新增一个键对值 (lock,1),再次通过setnx尝试修改lock的值时,会发现lock值始终唯一,这得益于SETNX的新增特点:SETNX只能添加不存在的键值,后两次setnx lock会因为键lock已经存在于redis而无法成功SETNX这种只能添加新键的特点可以用来实现锁,并且因为Redis是单线程的,多个线程只能串行进行,不会出现有多个线程同时SETNX的情况,也就不会有线程安全问题 - 为了防止出现在set锁后程序出问题导致DEL锁没有执行的情况,可以给锁加TTL,业务普遍的执行时间在1s以内,我们可以设置TTL为10s左右
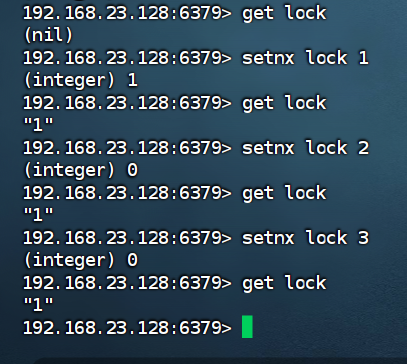
接下来实现代码逻辑
先添加获取与释放锁的逻辑代码,在ShopServiceImpl类中添加方法
1 | private boolean tryLock(String key){ |
修改业务逻辑
提取并将缓存穿透的代码封装成方法 queryWithPassThrough:
1 | public Shop queryWithPassThrough(Long id){ |
基于缓存穿透方法完成互斥锁方法,释放锁用finally包裹,不管是否异常都释放锁
1 | public Shop queryWithMutex(Long id){ |
queryById只需要调用 queryWithMutex方法即可:
1 | public Result queryById(Long id) { |
由于本地访问较快,可以添加休眠模拟重建延迟,使用JMeter进行并发测试
先在queryWithMutex中添加休眠,模拟重建的延迟(因为本地访问速度很快)
1 | shop = getById(id); |
清空缓存数据,并用 1000个线程Remp_up为5s对其进行访问

如果idea终端仅有一个数据库的查询语句说明没有问题
1 | DEBUG 116592 --- [o-8081-exec-202] com.hmdp.mapper.ShopMapper.selectById : ==> Preparing: SELECT id,name,type_id,images,area,address,x,y,avg_price,sold,comments,score,open_hours,create_time,update_time FROM tb_shop WHERE id=? |
3.5.2 基于逻辑过期解决缓存击穿问题
在查询缓存时未命中说明不是热点key(通常会做缓存预热把热点key提前存入缓存),直接返回空
- 命中则根据逻辑过期做缓存击穿解决
- 由value判断是否过期
- 未过期正常返回信息
- 过期尝试获取锁
- 不能获取说明其他线程在更新,先返回旧数据
- 能获取锁则开启新线程,先返回旧数据,新线程去数据库查询数据,写入缓存,设置逻辑过期TTL,释放锁
- 由value判断是否过期
流程图如下:
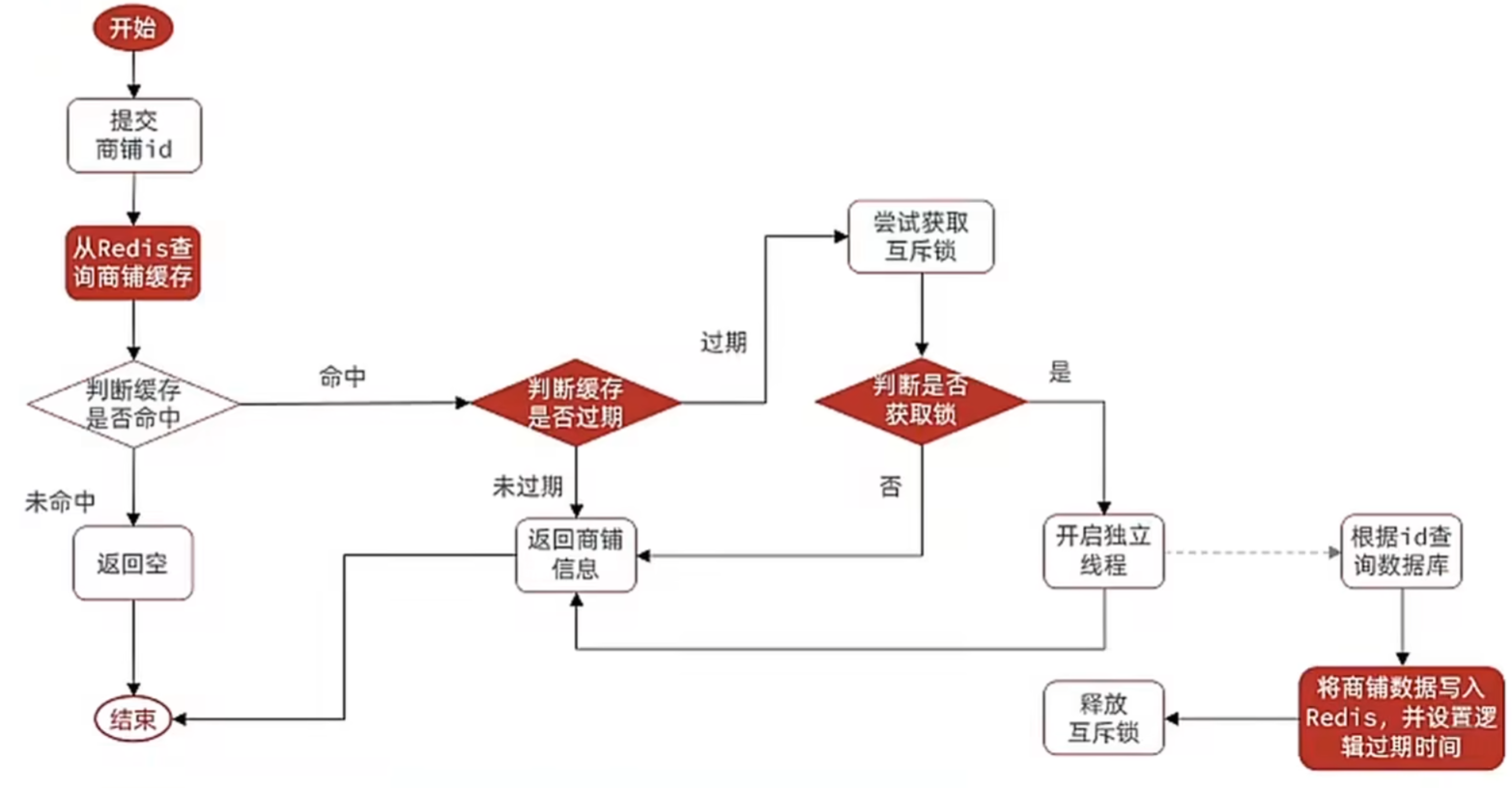
逻辑实现:
- 考虑如何添加逻辑过期时间
直接在Shop类添加对应的value字段是可以的,但违反了开闭原则(开放封闭性),所以需要新建实体类 - 先进行数据预热
新建工具类 redisData,包含属性data存放shop,以及逻辑过期时间,
1 |
|
写入逻辑过期时间
1 | private void saveShop2Redis(Long id,Long expireSecond){ |
通过单元测试测试是否存入了Redis
1 |
|
测试发现RESP中确实存入了对应的数据,并且添加了逻辑过期时间
1 | { |
完成queryWithLogicalExpire方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39//线程池
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
//缓存穿透
public Shop queryWithLogicalExpire(Long id) {
//从Redis中查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
//未命中
if (StrUtil.isBlank(shopJson)) {
return null;
}
//命中,判断逻辑过期
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
if(expireTime.isAfter(LocalDateTime.now())){
return shop;
}
//过期重建缓存
//获取互斥锁
boolean isLock = tryLock(LOCK_SHOP_KEY + id);
if(isLock){
//获取成功后开启重建线程
CACHE_REBUILD_EXECUTOR.submit(()->{
try {
this.saveShop2Redis(id,20L);
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
//释放锁
unLock(LOCK_SHOP_KEY+id);
}
});
}
return shop;
}
接下来进行测试,在 saveShop2Redis方法中设置线程休眠200ms,模拟缓存重建的延迟,测试目的是在高并发情况下是否会出现多个线程同时进行重建的情况以及数据一致性是否符合预期(重建未完成先返回旧数据)
先修改数据库信息,这里还是选择修改id=1的数据,把”103茶餐厅”改为了”135茶餐厅”
然后使用Jmeter测试,100线程Ramp-up设置2s,运行可以发现结果树最开始的http请求响应数据都是旧数据103,而到了11进程之后,线程的时间在200ms后,休眠解除,成功重建了缓存,进程信息就都是135了
3.6 缓存工具的封装
可以基于Redis封装一个工具类,实现以下需求:
方法1:将任意java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
1
2
3public void set(String key, Object value, Long time, TimeUnit unit){
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value),time,unit);
}方法2:将任意java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
1
2
3
4
5
6
7
8public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit){
RedisData<Object> redisData = new RedisData<>();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}方法3:根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
由于这里是工具类,通用方法就不能再返回Shop类型了,可以将可能有多种类型的参数定义为泛型,比如这里的返回类型,id属性,
还需要传入查询数据库逻辑的有参有返回值的函数(Function),用以根据id查询数据
并且由于类型的不确定,key的前缀和锁的前缀这些常量基本上都需要设置参数,让调用者自己传入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public <R,ID> R queryWithPassThrough(String keyPrefix, ID id, Class<R> type, Function<ID,R> dbFallback,Long time, TimeUnit unit){
//从Redis中查询商铺缓存
String key = keyPrefix + id;
String json = stringRedisTemplate.opsForValue().get(key);
//查询到数据则返回
if(StrUtil.isNotBlank(json)){
//反序列化
return JSONUtil.toBean(json, type);
}
//是否空
if(json!=null){
return null;
}
R r = dbFallback.apply(id);
//未查到则移交数据库查询并存入信息
//数据库未查到
if (r == null) {
//Redis写入空值 解决缓存穿透
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
return null;
}
//查到数据,写入redis
this.set(key,r,time,unit);
return r;
}1
2
3
4
public Result queryById(Long id) {
Shop shop = cacheClient.queryWithPassThrough(CACHE_SHOP_KEY,LOCK_SHOP_KEY,id,Shop.class, this::getById,CACHE_SHOP_TTL,TimeUnit.MINUTES);
}方法4:根据指定的key查询缓存,并反序列化为指定类型,利用逻辑过期解决缓存击穿问题
将
queryWithLogicalExpire以及它所调用的tryLock,unLock一起copy一份,并根据上面方法3的修改思路,更改queryWithLogicalExpire,令其成为通用方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42//线程池
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
//缓存穿透-逻辑过期
public <R,ID> R queryWithLogicalExpire(String keyPrefix,String lockKeyPrefix,ID id,Class<R> type,Function<ID,R> dbFallback,Long time, TimeUnit unit) {
//从Redis中查询商铺缓存
String key = keyPrefix + id;
String json = stringRedisTemplate.opsForValue().get(key);
//未命中
if (StrUtil.isBlank(json)) {
return null;
}
//命中,判断逻辑过期
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);
LocalDateTime expireTime = redisData.getExpireTime();
if(expireTime.isAfter(LocalDateTime.now())){
return r;
}
//过期重建缓存
//获取互斥锁
boolean isLock = tryLock(lockKeyPrefix + id);
if(isLock){
//获取成功后开启重建线程
CACHE_REBUILD_EXECUTOR.submit(()->{
try {
//查数据库
R r1 = dbFallback.apply(id);
//写入Redis
this.setWithLogicalExpire(key,r1,time,unit);
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
//释放锁
unLock(lockKeyPrefix+ id);
}
});
}
return r;
}在test中测试,运行后RESP有逻辑过期时间,等待逻辑过期厚,在jmeter中测试,IDEA只有一条查询说明封装没有问题
1
2
3
4
5
6
7
8
9
10
11
private CacheClient cacheClient;
private ShopServiceImpl shopService;
void testSaveShop() throws InterruptedException {
Shop shop = shopService.getById(1L);
cacheClient.setWithLogicalExpire(CACHE_SHOP_KEY+1L,shop,10L, TimeUnit.SECONDS);
}方法5 根据指定的key查询缓存,并反序列化为指定类型,利用互斥锁解决缓存击穿问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50//缓存穿透-互斥锁
public <R,ID>R queryWithMutex(String keyPrefix,String lockKeyPrefix,ID id,Class<R> type,Function<ID,R> dbFallback,Long time, TimeUnit unit) {
//从Redis中查询商铺缓存
String key = keyPrefix + id;
String json = stringRedisTemplate.opsForValue().get(key);
//查询到数据则返回
if (StrUtil.isNotBlank(json)) {
return JSONUtil.toBean(json, type);
}
//到这里只可能是null或"" 判断是否为"",""需要直接返回,null则进继续查数据库
if (json != null) {
return null;
}
String lockKey = lockKeyPrefix + id;
R r = null;
try {
boolean isLock = tryLock(lockKey);
if (!isLock) {
//获取锁失败,休眠
Thread.sleep(50);
return queryWithMutex(keyPrefix,lockKeyPrefix,id,type,dbFallback,time,unit); //递归啊...
}
r= dbFallback.apply(id);
//未查到则移交数据库查询并存入信息
//数据库未查到
// 测试 模拟重建延迟
//Thread.sleep(200);
if (r == null) {
//Redis写入空值 解决缓存穿透
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
//查到数据,写入redis
this.set(key,r,time,unit);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
//释放锁
unLock(lockKey);
}
return r;
}
TODO
4 优惠券秒杀
4.1 全局唯一ID
4.1.1 全局ID生产器
在本业务中,每个商铺都可以发布优惠券,用户抢购时,会生成订单并保存到
tb_voucher_order这张表中,而如果这张订单表使用了数据库的自增id,容易引发问题:- id规律明显
- 受单表数据量限制
- 单表所能存放的数据量终究是有限的,如果业务规模达到了需要分表分库的地步,这时自增长会出现不同表几个数据的id一样,可我们知道在逻辑上这些表其实是一张表,数据id唯一
为了解决这种问题,需要使用
全局ID生成器:是一种在分布式系统下用来生成全局唯一ID的工具,满足一下特性:- 唯一性
- 高可用
- 高性能
- 递增性:保证大体上的递增,可以提高数据库B+树插入时的效率
- 安全性
redis在数据库外,因此可以不受分表的影响,为了安全,不直接使用自增数值,需要拼接一些其他信息:
使用Long型数据:
1bit的符号位为零
31bit的时间戳,以秒为单位可以存21亿秒,约69年
32bit序列号,秒内的计数器,每秒可存2^32个ID
除了Redis自增方法,还有UUID,数据库自增,雪花算法,UUID不太适合在这里用,snowflake算法可以考虑,(雪花算法是1+41时间戳+10机器码+12序列号)
redis单值自增最大为2^64,但我们提供的序列是32位超出会出问题(虽然不太可能超),可以为序列号添加字段加强唯一性
接下来实现工具类
RedisIdWorker1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public class RedisIdWorker {
private static final long BEGIN_TIMESTAMP =1777939200L;
//序列号位数
private static final int COUNT_BITS = 32;
private StringRedisTemplate stringRedisTemplate;
public long nextId(String keyPrefix){
//生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond-BEGIN_TIMESTAMP;
//生成序列号
//生成日期
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
return timestamp<<COUNT_BITS | count;
}
// public static void main(String[] args) {
// LocalDateTime time = LocalDateTime.of(2026, 5, 5, 0, 0, 0);
// long second = time.toEpochSecond(ZoneOffset.UTC);
// System.out.println("second = " + second);
// }
}用LocalDataTime获取时间戳的起始时间,利用Redis自增和字符串拼接生成序列号,最后拼接生成ID
接下来在Test一下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private RedisIdWorker redisIdWorker;
private ExecutorService executorService = Executors.newFixedThreadPool(500);
void testIDWorker() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(300);
Runnable task = ()-> {
for(int i=0;i<100;i++) {
long id = redisIdWorker.nextId("order");
System.out.println("id = " + id);
}
latch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
executorService.submit(task);
}
latch.await();
long end = System.currentTimeMillis();
System.out.println("time = " + (end-begin));
}运行后ID格式正确,且Time值偏差不大2000左右,证明能正常生成ID
4.2 优惠券秒杀下单
- 每个店铺都可以发布优惠券,分为平价券和特价券,评价券可以任意购买,而特价券需要秒杀抢购,
- 相关联的表有
tb_voucher:存优惠券的基本信息,优惠金额,使用规则等tb_seckill_voucher:优惠券的库存,开始抢购时间,结束抢购时间。这些信息一般是特价优惠券这类需要秒杀的业务需要使用的
- 项目中已经实现了添加优惠券的代码
1 | / |
1 | / |
1 |
|
由于我们没有后台管理界面,所以使用postman工具实现
发送JSON格式请求到http://localhost:8081/voucher/seckill ,body如下:
1 | { |
刷新数据库,数据成功填入,并且刷新前端界面出现新优惠券,点击限时抢购提示功能未完成,所以下面完成秒杀下单功能
- 下单时需要判断两点:
- 秒杀是否开始或结束
- 库存是否充足
大致流程如下:
提交优惠券ID,查询优惠券信息,
判断时间是否过期
- 过期返回错误
- 没有过期进行下一步
- 判断是否有库存
- 有则扣减,并创建订单,返回ID
- 没有返回错误
- 判断是否有库存
接下来实现方法
1 |
|
1 | public interface IVoucherOrderService extends IService<VoucherOrder> { |
1 |
|
重启服务,抢购,数量减少,数据库有新增的数据,证明基础的下单功能完成
4.3 超卖问题
主要解决高并发下的订单问题(比如同时有大量用户抢购引发的问题)
使用Jmeter测试,200线程并发,发送post请求到http://localhost:8081//voucher-order/seckill/ +自己的voucher_id,这里注意需要添加请求头(HTTP信息头管理器),值填自己的token

同时添加JSON断言
运行发现结果树种近一半的数据请求失败,聚合报告的异常率为45.5%
并且数据库表库存变成-9,订单数有109个,说明出现了超卖现象
- 解决方案:加锁
可供选择的有两种锁:悲观锁和乐观锁
悲观锁:
认为数据安全问题一定发生,在操作数据前加锁,保证线程串行执行
Synchronized和Lock都属于悲观锁
由于串行执行,这并不适合高并发场景
乐观锁:认为线程安全问题不一定发生,不加锁,仅在更新数据时判断是否有其他线程对其进行了修改
- 没有修改认为安全,自己进行数据修改
- 已经修改说明发生安全问题,此时可以重试或异常
乐观锁常见的判断数据是否修改的方法有两种:
- 版本号
- 为数据添加版本号version,每次查询都获取版本号,在判断是否可以扣减时,额外判断version是否为之前获取的值,是则version+1
- CAS法(Compere and set)
- 我们可以用stock标识充当version,判断stock是否变化替代判断version
只需要添加一个stock值判断即可实现
- 版本号
1 | //减库存 |
修正数据库数据后Jmeter测试,异常率90%左右,结果正常,并且数据正常
这里我们可以发现,成功率非常低,可以改进一下:
将判断stock是否相等扩大为stock>0
mysql的update操作会给字段加上排他锁,所以不会出现复写操作
因为是原子操作 所以执行sql时候判断的stock>0 就是说明此时此刻stock>0 不存在线程切换 多个线程同时stock>0的情况
1
2
3
4
5//减库存
boolean success = seckillVoucherService.update().setSql("stock = stock - 1")
.eq("voucher_id", voucherId)
+ .gt("stock",0)
.update();init数据后重新执行,发现正好用完所有订单
4.4 一人一单
秒杀通常是一人一单的,这就需要我们完善带代码,要求一个用户同一个优惠券只能抢购一张
具体做法是根据优惠券id和用户id查询是否已经抢过相同的订单,再进行后续的减库存操作
1 | @Override |
测试发现没有实现,用户还是下了几单,这个问题和上面的超卖问题很像,多线程并发查询数据,count都>0,导致多个线程继续执行了后续操作
- 需要再一人一单逻辑到存入数据库后的这部分过程加锁,并且无法用乐观锁
- 将这部分逻辑抽离成方法
creatVoucherOrder并注入事务,seckillVoucher的事务注解就可以删了
给锁加在方法上可以,但是这样就把调用这个方法的所有对象都锁了(方法锁的是this这个对象,所有对象公用一把锁),修改之后就只锁传入相同userId的线程,相当于串行,效率很低还会引发其他问题,我们可以给userId加锁
同时由于事务的提交在锁释放后,这期间可能还会出现并发问题,所以可以给整个 creatVoucherOrder方法加锁,先获取锁再进入函数,这样函数执行完说明数据一定也写入数据库了
这也是为什么要抽取出来一个方法,因为要将事务添加到这个方法上面,从而可以让锁包裹住事务。
1 |
|
toString转换时是new String的,这样不能保证同一个userId每次都转成一样的字符串,因此需要
intern(),返回字符串的规范表示,即在字符串常量池找到等于这个string对象的字符串由(equals(object)方法确定),则返回池中的字符串;否则将此String对象添加到池并返回对该String对象的引用
这里idea对return的方法警告:事务自调用,这是由于事务生效是spring对当前类进行了动态代理,拿到了代理对象,用这个对象做事务处理,而我们return的实际上是this调用的非代理对象(当前的VoucherOrderService对象),这样是没有事务功能的,
- 所以我们需要拿到事务的代理对象,这里借助api:
AopContext.currentProxy(),需要添加依赖:
1 | <dependency> |
- 修改方法:
1 |
|
- 最后为启动类
HmDianPingApplication添加注解@EnableAspectJAutoProxy(exposeProxy=true)暴露代理对象
重置数据,Jmeter测试,只有一个请求成功,订单仅一个,业务成功实现
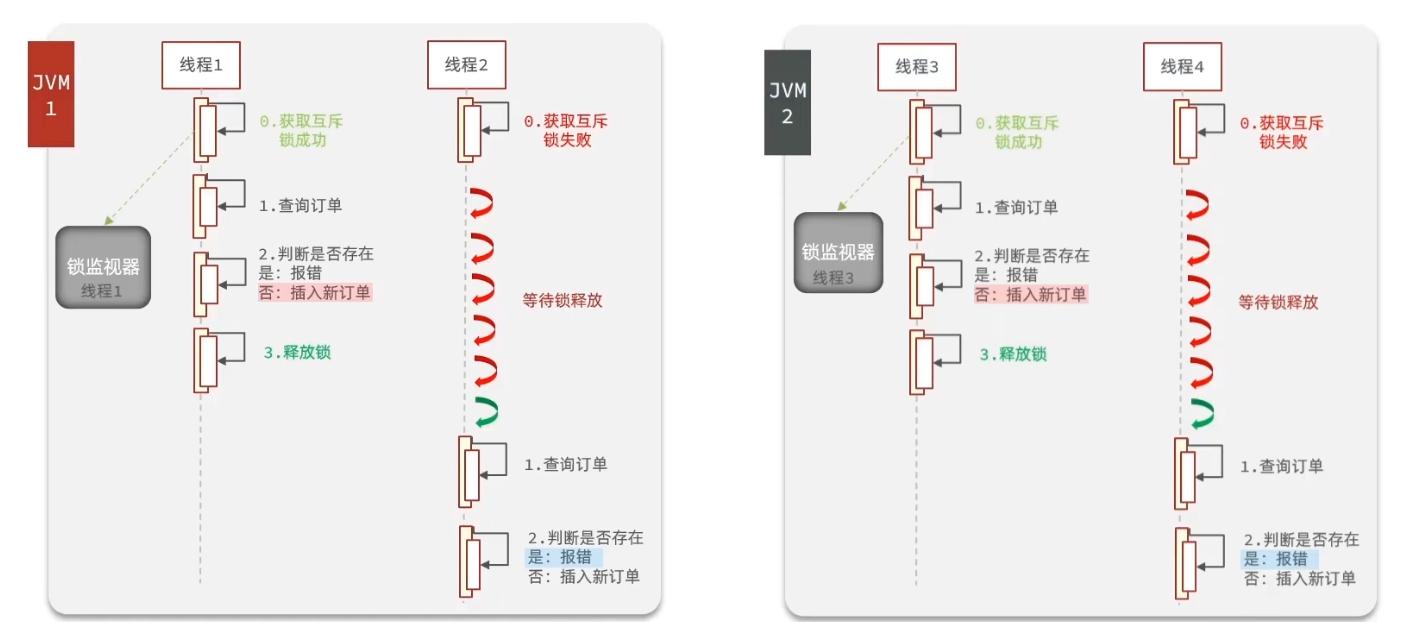
4.6 集群环境下的并发问题
加锁解决的一人一单安全问题仅仅适用单机情况,无法满足集群模式下的需求
启动两份服务,端口为8081,8082,修改nginx的conf目录下的nginx.conf文件,配置反向代理和负载均衡,令用户请求在这两个节点上负载均衡,模拟集群模式并测试
在获取代理对象处加断点,利用postman发送两次请求,用同一用户的token,发现两个服务都收到了请求,锁失效
这是因为分布式下两个JVM有各自的锁监视器,锁对象不同
5 分布式锁
前面提到集群下的锁问题可以借助分布式锁解决,我们可以用一个独立于JVM的锁监视器令JVM从它获取锁
- 分布式锁: 满足分布式系统或集群下的多进程可见并且互斥的锁
- 分布式锁应当满足:多进程可见,互斥,高可用,高性能,安全性等特性
- 常见的满足多进程互斥的方法有三种:| | MySQL | Redis | Zookeeper |
| ———- | :———————–: | :———————: | :——————————: |
| 多线程互斥 | 利用MySQL本身的互斥锁机制 | setnx这样的互斥命令 | 利用节点的唯一性和有序性实现互斥 |
| 高可用 | 好 | 好 | 好 |
| 高性能 | 一般 | 好 | 一般 |
| 安全性 | 断开连接,自动释放锁 | 利用锁超时时间,到期释放 | 临时节点,断开连接自动释放 |
5.1 基于Redis实现互斥锁
实现分布式锁需要实现两个基本方法
获取锁
互斥:确保只能有一个线程获取锁
利用set确保原子性
1
SET lock EX 10 NX
非阻塞:尝试一次成功返回true,失败返回false
释放锁
- 手动释放
- 超时释放:获取锁时添加一个超时时间
我们可以定义一个类,实现下面的接口;
1 | public interface ILock { |
完成实现方法:
1 | public class SimpleRedisLock implements ILock{ |
修改 seckillVoucher方法,用手动创建锁代替 synchronized
1 |
|
if(!islock)添加断点调试,init数据库数据,用postman发送之前的两个请求,发现两个的变量islock一个true,一个false,成功锁住
5.2 解决Redis分布式锁的误删问题
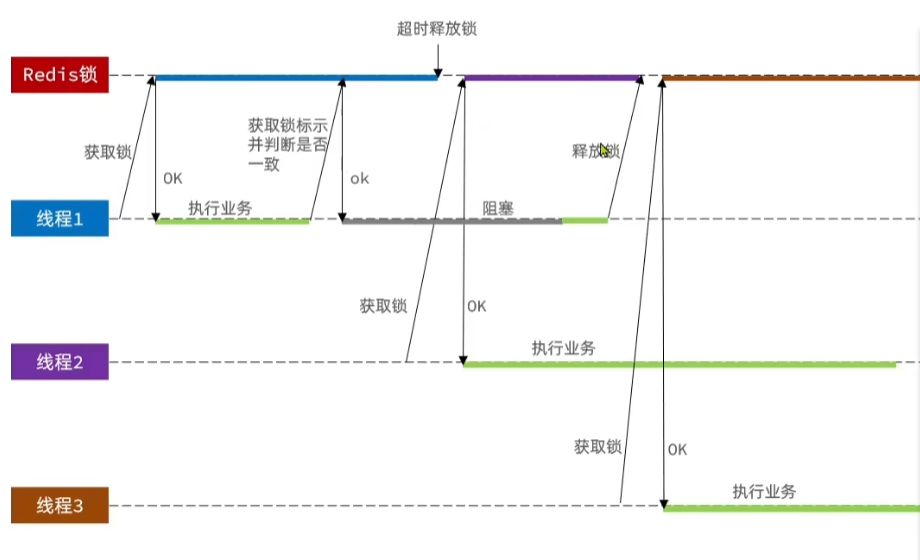
4.7.1的业务逻辑并不完善,比如
- 如果线程1获取到redis锁后发生阻塞,阻塞时间超过了锁的ttl,锁自动释放,
- 此时线程2获取锁,这时线程1阻塞解决,完成业务并释放锁,把线程2的锁释放了
- 这时线程3成功获取锁并执行业务,就会出现线程2,3同时执行业务的情况,出现并发问题
我们需要在业务成后,释放锁时判断获取的锁标识是否一致,预期流程如下:
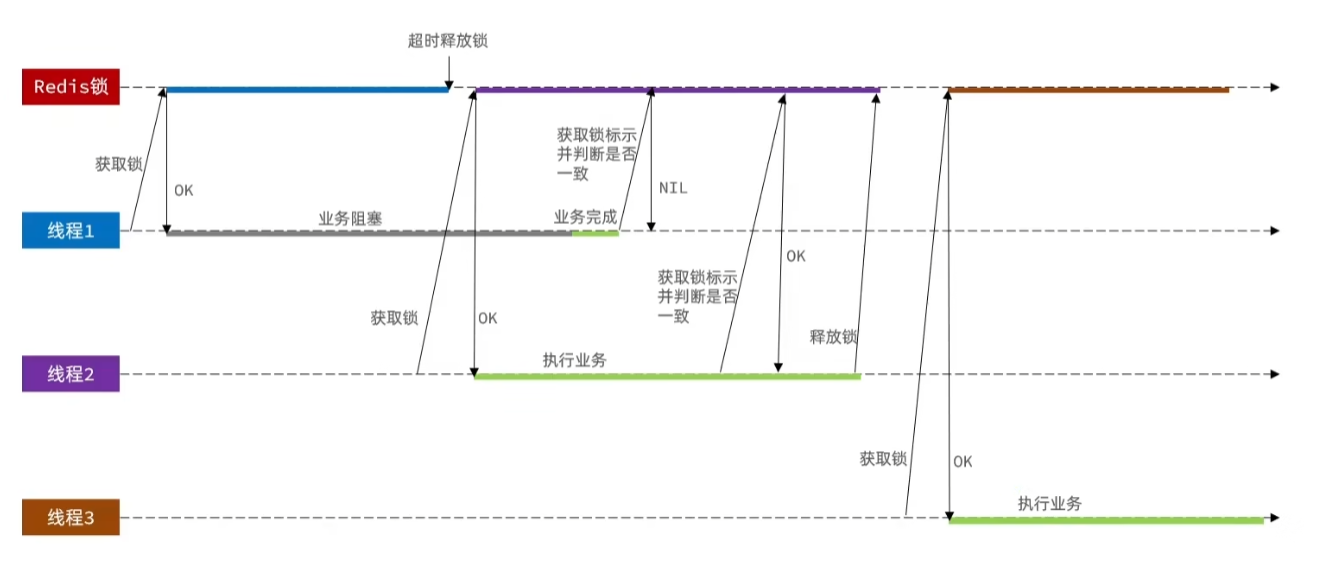
具体方法如下:
- 在获取锁时存入线程标识(例如UUID表示)
- 释放锁时判断标识是否一致,一致释放锁,否则不释放
使用UUID拼接生成线程标识前缀,与线程id拼接生成线程标识,并修改unlock方法
1 | public class SimpleRedisLock implements ILock{ |
调试发现可以解决误删
5.3 原子性问题
还有一种极端情况
- 线程1在即将释放时(已经判断过标识)阻塞(JVM垃圾回收,FullGC)
- 线程2获取锁,执行业务时线程1恢复,删除了线程2的锁
- 线程3获取锁执行业务,出现2,3并发
5.4 lua
Redis提供了lua脚本功能,能够在一个脚本中编写多条Redis命令,确保多条命令执行的原子性,关于lua的语法,参考https://www.runoob.com/lua/lua-tutorial.html
Redis内置了函数调用用法如下:
1 | redis.call('命令名称',key,'其他参数',...) |
例如set name jack
1 | redis.call(set,'name','jack') |
命令写好后,可以用EVAL执行

1 | EVAL "return redis.call('set','name','jack')" 0 |
这里的0是传入的key参数的数量
如果key,value不想写死,作为参数传递,可以用数组,key类型参数会放在KEYS数组,value类型放在ARGV数组
1 | EVAL "return redis.call('set',KEYS[1],ARGV[1])" 1 name Rose |
我们可以将unlock的逻辑用lua脚本代替
1 | -- 锁的key |
在java代码中,可以通过 RedisTemple调用lua脚本的API,其中的方法 execute
1 | public <T> T execute(RedisScript<T> script, List<K> keys, Object... args) { |
先创建lua脚本
1 | if(redis.call('get',KEYS[1])==ARGV[1]) then |
静态初始化lua脚本增加效率
1 | //lua脚本初始化 |
修改unLock()方法
1 |
|
这样一行代码保证了原子性,不会出现极端情况引发的问题
5.5 Redisson优化
5.5.1 Redisson
基于setnx的实现的分布式存在下面的问题:
- 不可重入:同一个线程无法多次获取同一把锁
- 不可重试:获取锁知尝试一次就返回false,没有重试机制
- 超时释放:锁超市释放虽然可以避免死锁,但如果业务执行时间过长,也会导致锁释放,有安全隐患
- 主从一致性:如果Redis提供了主从集群,主从同步存在延迟,当主宕机时,如果从并未同步主中的锁数据,就会出现锁实现
这些功能实现起来十分复杂,所以我们可以借助现有的框架 Redisson
- redisson :在Redis基础上实现的Java驻内存数据网格(In-Memory Data Grid),不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中包含分布式锁的实现。官网 Github地址
使用Redisson需要先引入依赖:
1 | <dependency> |
在Config包实现 RedisConfig类
1 |
|
在 seckillVoucher方法中调用,只需要注入 RedissonClient后,替换即可
1 | //创建锁对象 |
使用postman发送一个请求,发现能够获取信息
1 | { |
也可以用Jmeter测试,最终数据库都能正常更新数据
5.5.2 Redisson可重入锁原理
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ,如果是对于synchronized而言,他在c语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
在redission中,我们也支持支持可重入锁
在分布式锁中,采用hash结构用来存储锁,其中外层key表示表示这把锁是否存在,内层key表示当前这把锁被哪个线程持有
在下面这个逻辑中,method1在方法内部调用method2,method1和method2出于同一个线程,那么method1已经拿到一把锁了,想进入method2中拿另外一把锁,必然是拿不到的,于是就出现了死锁
1 |
|
所以我们需要额外判断,method1和method2是否处于同一线程,如果是同一个线程,则可以拿到锁,并将state
+1,之后执行method2中的方法,释放锁,释放锁的时候也只是将state进行-1,只有减至0,才会真正释放锁由于我们需要额外存储一个state,所以用字符串型
SET NX EX是不行的,需要用到Hash结构,但是Hash结构又没有NX这种方法,所以我们需要将原有的逻辑拆开,进行手动判断逻辑分开就需要保证原子性,所以我们使用Lua脚本实现,流程如下图
lua脚本实现如下:

获取锁:
1 | -- 锁的key |
释放锁:
1 | --- 释放锁 |
可以通过测试类测试上面的method1,method2方法,结合RESP键lock的值判断是否成功
调试完成后的终端信息如下
我们可以查看源码
获取锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}这里将lua脚本用字符串写死了
释放锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;",
Arrays.asList(getName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
}
5.5.3 Redisson锁重试和WatchDog机制
之前空参的tryLock(),不能重试,现在可以加参数看一下源码
tryAcquireAsync:
1 | private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) { |
tryLockInnerAsync:
1 | <T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) { |
scheduleExpirationRenewal:实现自动续约
1 | private void scheduleExpirationRenewal(long threadId) { |
renewExpiration:更新有效期
1 | private void renewExpiration() { |
renewExpirationAsync:刷新有效期
1 | protected RFuture<Boolean> renewExpirationAsync(long threadId) { |

5.5.4 Redisson的multiLock原理
前面已经了解了Redisson如何解决可重入性和超时释放的问题,现在来看一下主从一致性
主从模式下从节点负责读,主节点会同步数据给从节点,当主节点宕机时,哨兵监测到并选出从节点替代主节点,如果主从同步未完成,新的从节点未获取到锁的信息,这时其他线程就能够获取到锁,出现并发安全问题
Redisson的`解决方法是摒弃主从将所有节点都为独立的redis node,相互之间没有关系,都可以做读写
之前只需要向Master主节点获取锁,现在必须依次向多个Redis节点获取锁,这样一个宕机其他也能获取到锁
我们还可以额外给这些节点每一个都建立主从,这样节点不可用时,从节点顶替,虽然可能获取不到锁,但由于逻辑是所有节点都要能获取锁,最后才能成功获取锁,这种情况是会失败的
下面我们就使用三个节点,不搭建主从测试一下
首先配置两个新节点(复制并修改Redis的conf文件,主要改端口和密码,最后连接,可以用RESP测试是否能够连上),在 RedisConfig添加配置
添加:
1 |
|
在单元测试中创建连锁
1 |
|
之后调试并结合RESP验证效果
成功后我们来看一下RedissonMultiLcok的tryLock实现,跟进tryLock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
// try {
// return tryLockAsync(waitTime, leaseTime, unit).get();
// } catch (ExecutionException e) {
// throw new IllegalStateException(e);
// }
long newLeaseTime = -1;
if (leaseTime != -1) {
if (waitTime == -1) {
newLeaseTime = unit.toMillis(leaseTime);
} else { //设置了等待时间,调整释放锁的时间保证能够重入
newLeaseTime = unit.toMillis(waitTime)*2;
}
}
//当前时间
long time = System.currentTimeMillis();
//剩余等待时间
long remainTime = -1;
if (waitTime != -1) {
remainTime = unit.toMillis(waitTime);
}
//锁的等待时间,实际上与remainTime相等
long lockWaitTime = calcLockWaitTime(remainTime);
//锁失败的限制,return 0
int failedLocksLimit = failedLocksLimit();
//获取成功的锁
List<RLock> acquiredLocks = new ArrayList<>(locks.size());
for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
try {
if (waitTime == -1 && leaseTime == -1) {
lockAcquired = lock.tryLock();
} else {
long awaitTime = Math.min(lockWaitTime, remainTime);
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
}
} catch (RedisResponseTimeoutException e) {
unlockInner(Arrays.asList(lock));
lockAcquired = false;
} catch (Exception e) {
lockAcquired = false;
}
//成功就将将锁放进acpuiredLocks
if (lockAcquired) {
acquiredLocks.add(lock);
} else {
//锁总数-已经获取的锁的个数==
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
break;
}
if (failedLocksLimit == 0) {
unlockInner(acquiredLocks);
if (waitTime == -1) { //如果是不重试的锁直接false
return false;
}
//重试
failedLocksLimit = failedLocksLimit();
acquiredLocks.clear();
// reset iterator
while (iterator.hasPrevious()) {
iterator.previous();
}
} else {
failedLocksLimit--;
}
}
//剩余时间不为-1,更新,获取现在剩余的时间
if (remainTime != -1) {
remainTime -= System.currentTimeMillis() - time;
time = System.currentTimeMillis();
//获取锁耗尽了等待时间,即获取锁超时
if (remainTime <= 0) {
//释放已获取的锁
unlockInner(acquiredLocks);
return false;
}
}
}
//锁的释放时间,==-1时看门狗自动续有效期
if (leaseTime != -1) {
List<RFuture<Boolean>> futures = new ArrayList<>(acquiredLocks.size());
//重新设置每一个已获取的锁的有效期,保持一致
for (RLock rLock : acquiredLocks) {
RFuture<Boolean> future = ((RedissonLock) rLock).expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS);
futures.add(future);
}
for (RFuture<Boolean> rFuture : futures) {
rFuture.syncUninterruptibly();
}
}
return true;
}
5.5.5 小结
- 不可重入Redis分布式锁
- 原理:利用setnx的互斥性;利用ex避免死锁;释放锁时判断线程标识
- 缺点:不可重入,无法重试,锁超时失效
- 可重入的Redis分布式锁
- 原理:利用hash结构,记录线程标识和重入次数;利用
WatchDog延续锁的时间;利用信号量控制锁重试等待 - 缺陷:redis宕机会引发锁失效问题
- 原理:利用hash结构,记录线程标识和重入次数;利用
Redisson的multiLock- 原理:多个独立的Redis节点,必须在所有节点都获取到重入锁,才能成功
- 缺陷:运维成本高,实现复杂
6 Redis优化秒杀
6.1 优化思路
在我们之前的优惠券抢购流程,是一个线程串行执行的,并且其中的查询优惠券,查询订单,减库存,创建订单的任务都需要查询数据库,而数据库处理并发的能力是比较弱的,所以我们需要优化性能,
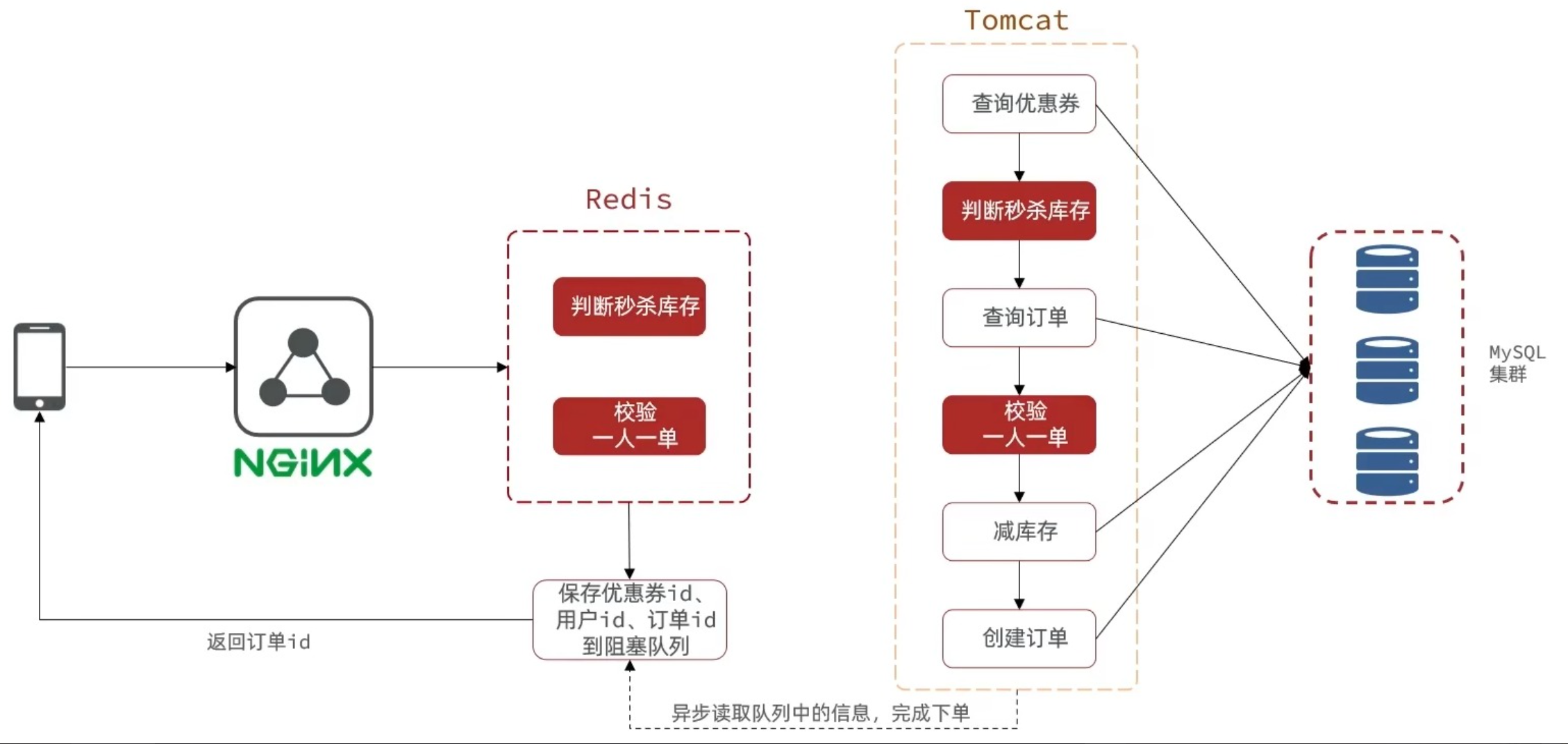
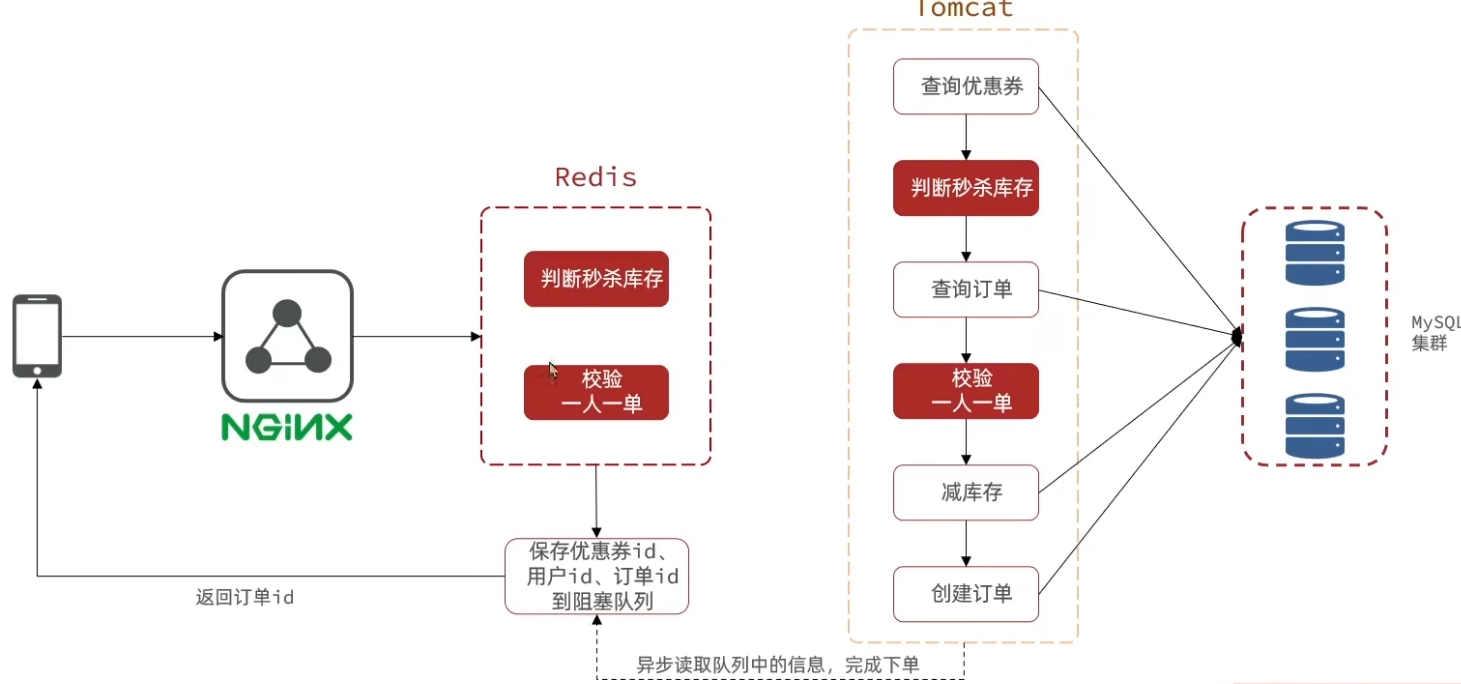
优化方案:可以将流程分成两个部分,耗时短的判断秒杀库存和校验一人一单,需要数查询据库的用时较长的其他部分,交由两个线程,用时短的判断校验功能主线程可以交由redis解决,用时久的任务交给另一个独立线程解决
我们不能再采用线性结构处理,所以redis处理后需要在阻塞队列存入特征信息(比如优惠券id,用户id,订单id),方便独立线程处理具体任务
我们先解决Redis部分的功能,
- 首先是存储问题
用户id和优惠券id,后者结构简单,string存储即可,
用户id结构复杂,我们期望记录优惠券被哪些用户购买过,即一个key存入多个值,并且保存的用户id唯一, 所以使 用set集合
- 其次是实现,由于库存充足后需要进行多个流程,为了确保原子性,需要使用lua脚本,主线程第一步直接执行lua脚本,由返回的结果执行异常或存入阻塞队列的操作,安全性好。
6.2 Redis实现秒杀资格判断
前面我们已经分析过了实现方法,下面我们实现以下需求,改进秒杀业务,提高并发性能
- 新增秒杀优惠券的同时,将优惠券信息保存到Redis中,
- 基于Lua脚本,判断秒杀库存,一人一单,决定用户是否抢购成功
- 抢购成功,将优惠券id和用户id封装后加入阻塞队列
- 开启线程任务,不断从阻塞队列获取信息,实现异步下单功能
保存秒杀优惠券
1 | @Override |
postman发送post,添加秒杀券,body如下:
1 | { |
数据库和Redis能够看到新增秒杀券信息
下面完成lua脚本 seckill:
1 | -- 券id |
修改seckillVoucher方法,改用redis+lua脚本实现秒杀下单
1 | private static final DefaultRedisScript<Long> SECKILL_SCRIPT; |
最后postman发送请求,发现返回数据,不并且Redis中seckill:order:新增了value(就是自己的用户id),seckill:stock:库存从100变成了99,之后postman在重复发送请求显示不能重复下单
加入阻塞队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//阻塞队列,线程获取元素时,无元素一直等待,直到有元素
private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024);
//存入阻塞队列
//存数据 订单id
VoucherOrder voucherOrder = new VoucherOrder();
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
//用户id
voucherOrder.setUserId(userId);
//代金券id
voucherOrder.setVoucherId(voucherId);
//存入阻塞队列
orderTasks.add(voucherOrder);实现异步下单
这里期望线程在类初始化之后立刻执行,所以需要使用spring提供的注解
@PostConstruct–Bean的生命周期1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//线程池
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
private void init(){
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable{
public void run() {
while(true){
try {
//获取队列中的订单信息
VoucherOrder voucherOrder = orderTasks.take();
//创建订单
handlerVoucherOrder(voucherOrder);
} catch (Exception e) {
log.error("处理订单异常!",e);
}
}
}
}完成
handlerVoucherOrder方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25//处理订单 --异步
private void handlerVoucherOrder(VoucherOrder voucherOrder) {
Long voucherId = voucherOrder.getVoucherId();
//创建锁对象
//Redisson
RLock lock = redissonClient.getLock("lock:order:" + voucherId);
//获取锁
boolean isLock = lock.tryLock();
if (!isLock) {
log.error("不允许重复下单!");
return;
}
try {
proxy.creatVoucherOrder(voucherOrder);
} catch (IllegalStateException e) {
throw new RuntimeException(e);
}finally {
lock.unlock();
}
}
由于是异步下单,子线程,代理对象,锁和一些资源不能获取,需要修改部分代码
查看AopContext源码,它的获取代理对象也是通过ThreadLocal进行获取的,由于我们这里是异步下单,和主线程不是一个线程,所以不能获取成功
将proxy提入成员变量,再在主线程获取代理对象
1 | private IVoucherOrderService proxy; |
之后修改 creatVoucherOrder方法,传入参数改为 VoucherOrder对象,并移除已经不需要的创建订单对象(已经存入过阻塞队列了)
1 |
|
最后完整代码如下:
1 | package com.hmdp.service.impl; |
7 Redis消息队列实现异步秒杀
刚才使用了阻塞队列,其使用的是JVM的内存,为了防止高并发下的内存溢出我们给它设置了队列长度,可是如果队列存满就会引发新的内存溢出的问题
并且,服务宕机还会引发数据安全问题,比如用户已经下单,但数据没有同步数据库;或者队列取出的任务没有正常执行,后续也不会再执行
- 消息队列(Message Queue):最简单的消息队列模型包括三个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker )
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
消息队列可以解耦,提高工作效率,用实际举例就是使用快递柜,快递员送快递,消费者拿快递就是一个异步,如果没有快递柜,我们想要当面收取快递,有无法及时赶到,就只能让快递员一直等,这肯定是不现实的,这就可以看做一种耦合
我们可以使用现有的消息队列,比如rabbitmq,kafka等,也可以使用Redis提供的方案
- List:基于List结构模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
7.1 基于List实现消息队列
List数据结构是双向链表,容易模拟出队列效果,
我们可以用LPUSH+RPOP或RPUSH+LPOP实现进出队列
期望是实现无元素时的阻塞,但POP是是非阻塞的,所以需要换成BLPOP或BRPOP
优点:
- JVM以外的独立存储,不依赖JVM内存,不用担心存储上限的问题
- Redis的数据持久化,保证了数据安全
- 满足消息的有序性
缺点:
- 无法避免消息丢失
- 仅支持单消费者
7.2 PubSub实现消息队列
PubSub(发布订阅):是Redis2.0推出的消息传递模型,消费者可以订阅一个或多个channel,生产者向对应的channel发送信息后,所有订阅者都能收到相关消息
其常用命令如下:
- SUBSCRIBE channel [channel]:订阅一个或多个频道
- PUBLISH channel msg:向一个频道发送信息
- PSUBSCRIBE pattern [pattern]:订阅与pattern格式匹配的所有频道
上面PSUBSCRIBE允许使用通配符订阅,官网解释如下:
Subscribes the client to the given patterns.
Supported glob-style patterns:
- h?flo subscribes to hello, hallo and hxllo
- h*llo subscribes to hllo and heeeello
- h[ae]llo subscribes to hello and hallo, but not hillo
Use \ to escape special characters if you want to match them verbatim.
PubSub的优点:
- 采用发布订阅模式,支持多生产,多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失(发送数据但没人监听会直接丢失)
- 消息堆积有上限,超出时数据会丢失(发送消息有消费者监听,其会有一个缓存区缓存消息并处理,如果处理过慢会有消息堆积)
7.3 Stream实现消息队列
Stream是在Redis5.0引入的新数据类型,能够实现功能完善的消息队列
7.3.1 Stream的单消费模式
发送消息
1 | XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|id field value [field value ...] |
NOMKSTREAM:队列不存在是否自动创建,默认自动创建
[MAXLEN|MINID [=|~] threshold [LIMIT count]]:消息队列的最大消息数量
*|id :指定消息的唯一ID,*代表自动生成,格式为”时间戳-递增数字”
field value [field value …] :发送到队列的消息,entify,多个key-value键值对
1 | xadd users * name jack age 21 |
消息读取:
1 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
[COUNT count] :每次读取的消息最大数量
[BLOCK milliseconds] :没有消息时是否阻塞,阻塞时长,0永久阻塞
STREAMS key [key …] :从哪个队列读取消息,key为队列名
ID [ID …] : 指定起始的消息ID,返回大于该ID的消息,0为从第一个开始,$代表从最新的消息开始
示例:
1 | XREAD COUNT 1 STREAMS ss1 0 |
发现多个消费者都能重复读取该信息,也就是说消息有 持久化 ,但用$读取消息,由于消息都读取过了,没有最新消息
阻塞等待最新消息:
1 | XREAD COUNT 1 BLOCK 0 STREAM ss1 $ |
循环调用XREAD阻塞方式查询最新消息,实现持续监听的效果
1 | while(TRUE){ |
这种方式会出现漏读的情况:当读取到最新的消息并处理时,如果同时又有一条以上的消息到达消息队列,就会出现之后只读取最新的消息的情况
- XREAD命令的特点如下;
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
7.3.2 消费者组
消费者组(Consumer Group ):将多个消费者划分到一个组,监听同一个队列,具备以下特点:
消息分流
队列中的消息会分流给组内的不同消费者,而不是重复的消费者,从而加快消息处理的速度
消息标识
消费者组会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息,确保每一个消息都会被消费
消息确认
消费者获取消息后,消息处于pending状态,并存入一个
pending-list,当处理完成后,需要通过XACK来确认消息,标记为已处理,才会从pending-list移除
创建消费者组
1 | XGROUP CREATE key groupName ID [MKSTREAM] |
key: 队列名称
groupName: 消费者组名称
ID : 起始ID标示,常用$或0
[MKSTREAM] : 队列不存在时自动创建队列
其他常见命令
删除指定的消费者组
1
XGROUP DESTORY key groupName
给指定的消费者组添加消费者
1
XGROUP CREATECONSUMER key groupName consumerName
删除消费者组中指定的消费者
1
XGROUP DELCONSUMER key groupName consumerName
从消费者组读取消息
1
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
group: 消费者组名称
consumer: 消费者名称,消费者不存在自动创建
count: 查询的最大数量
BLOCK milliseconds: 没有消息的最大等待时间(ms)
NOACK: 无需手动ACK,获取到消息后自动确认
STREAMS key: 指定队列名称
ID: 获取消息起始ID:
- “>” :从下一个未消费的消息开始
- 其他:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始
消费者监听消息的基本思路
1 | while(true){ |
Stream类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读风险
- 有消息确认机制,保证消息至少被消费一次
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间, 可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度, 可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
7.3.3 Stream实现异步秒杀下单
- 需要先创建一个Stream类型的消息队列,命名为Stream.orders
- 修改lua脚本,在认定有抢购资格后,直接向stream.orders中添加消息,内容包含voucherId,userId,order
- 项目启动时,开启一个线程任务,尝试获取stream.orders的消息,完成下单
1 | XGROUP CREATE stream.orders g1 0 MKSTREAM |
下面修改Lua脚本
1 | -- 券id |
lua脚本新增了订单Id,并将信息发到了队列,需要修改seckillVoucher方法
1 |
|
修改线程完成下单
1 | private class VoucherOrderHandler implements Runnable{ |
post请求,进行压测,都能够通过
8 达人探店
8.1 发布探店笔记
探店笔记对应的表有两个
tb_blog: 包含图片中的标题,文字,图片等信息bt_blog_comments: 其他用户的评价
我们期望的需求如下:
点击首页下方的”+”能够发布探店图文
上传图片的代码如下
1 |
|
上面我们需要修改
SystemConstants.IMAGE_UPLOAD_DIR值为自己图片所在的地址,在实际开发中图片一般会放在nginx上或者是云存储上。这里简化处理
发送笔记的代码
1 |
|
8.2 查看探店笔记
需求:点击首页的探店笔记,会进入详情页面,我们现在需要实现页面的查询接口
实现查看发布探店笔记的接口
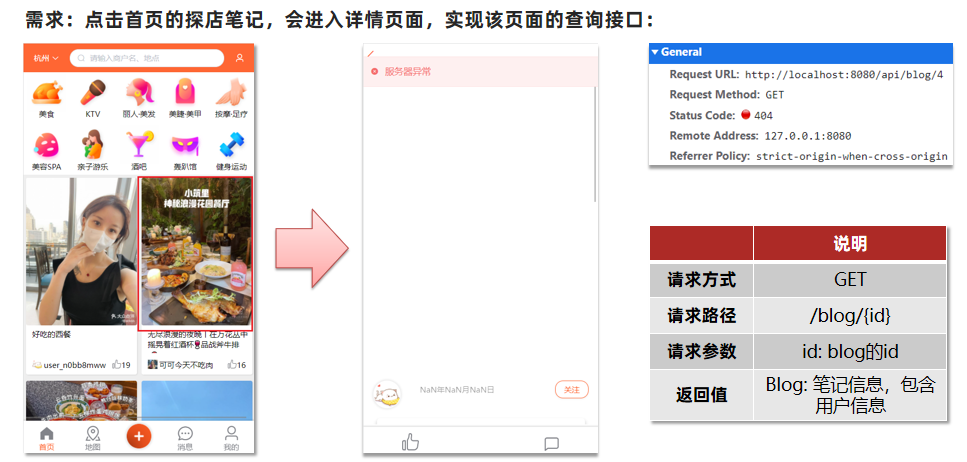
实现代码:
BlogServiceImpl
1 |
|
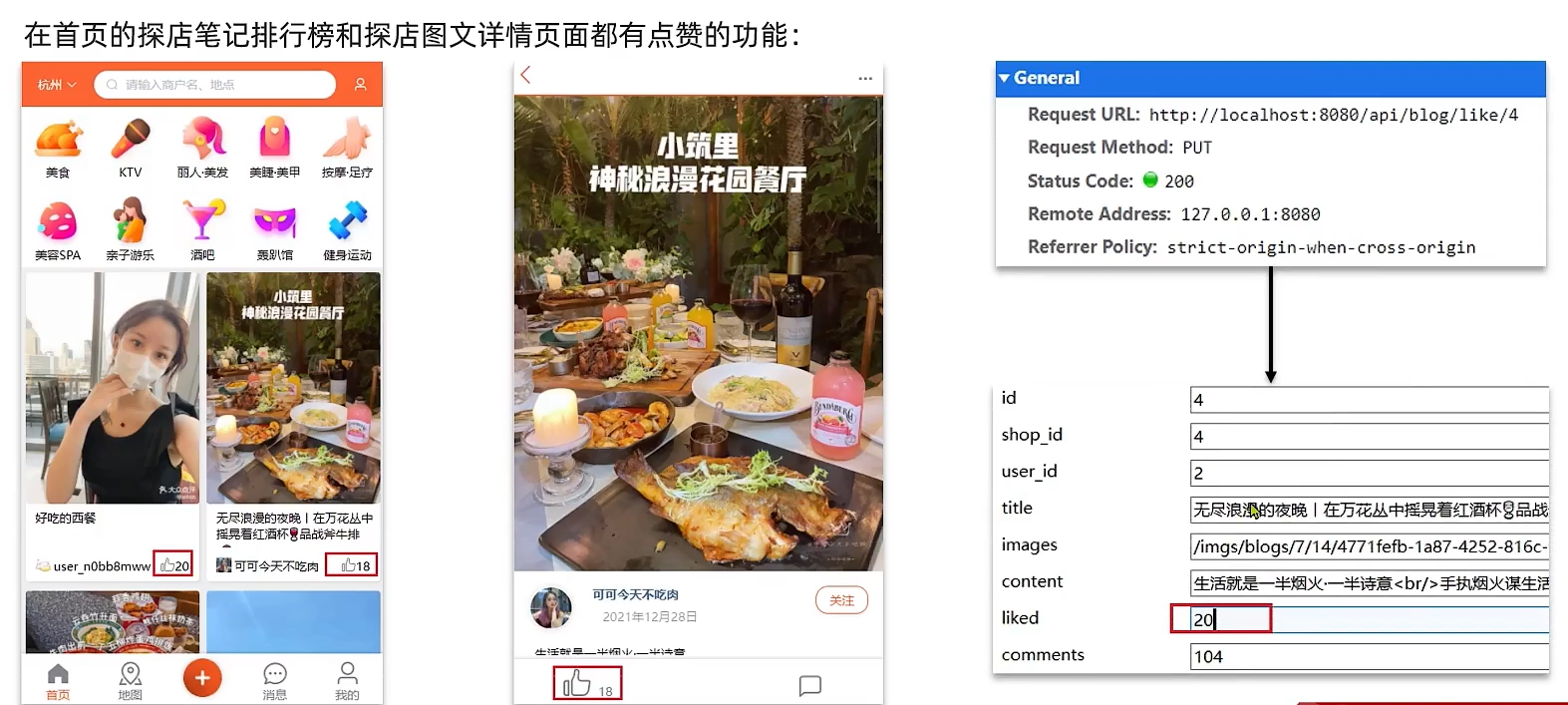
8.2 点赞
初始代码
1 |
|
问题分析:这种方式会导致一个用户无限点赞,明显是不合理的
造成这个问题的原因是,我们现在的逻辑,发起请求只是给数据库+1,所以才会出现这个问题
完善点赞功能
需求:
- 同一个用户只能点赞一次,再次点击则取消点赞
- 如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
实现步骤:
- 给Blog类中添加一个isLike字段,标示是否被当前用户点赞
- 修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1
- 修改根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLike字段
- 修改分页查询Blog业务,判断当前登录用户是否点赞过,赋值给isLike字段
为什么采用set集合:
因为我们的数据是不能重复的,当用户操作过之后,无论他怎么操作,都是
具体步骤:
1、在Blog 添加一个字段
1 |
|
2、修改代码
1 |
|
8.4 达人探店-点赞排行榜
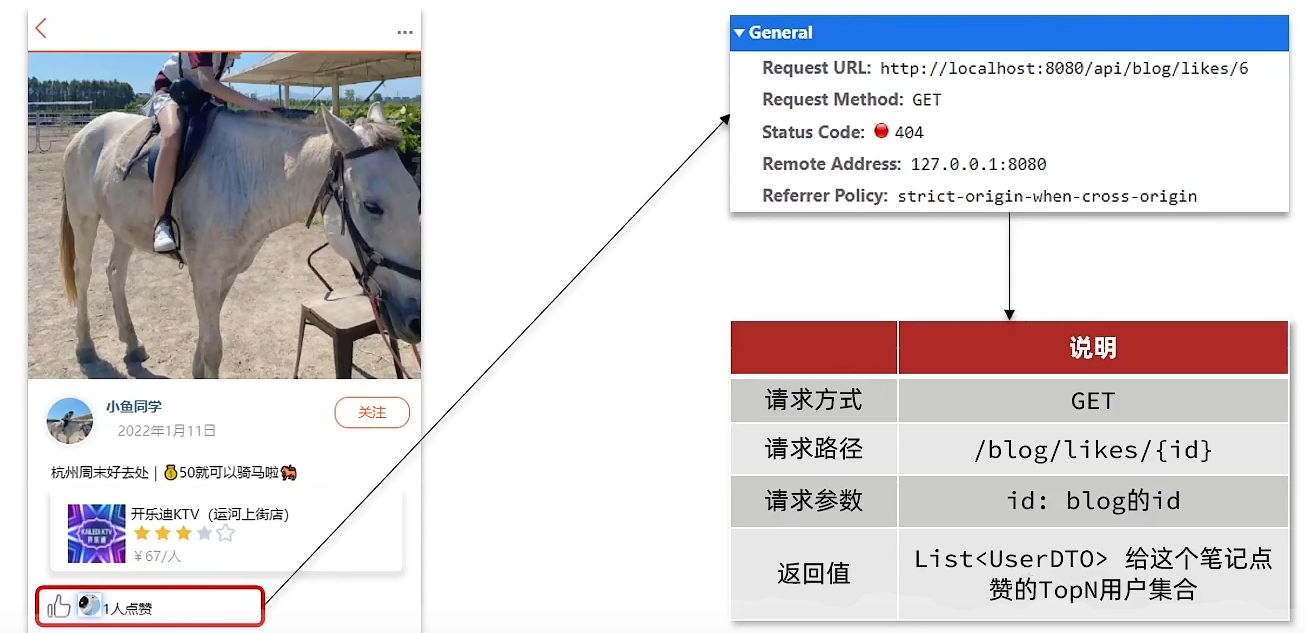
在探店笔记的详情页面,应该把给该笔记点赞的人显示出来,比如最早点赞的TOP5,形成点赞排行榜:
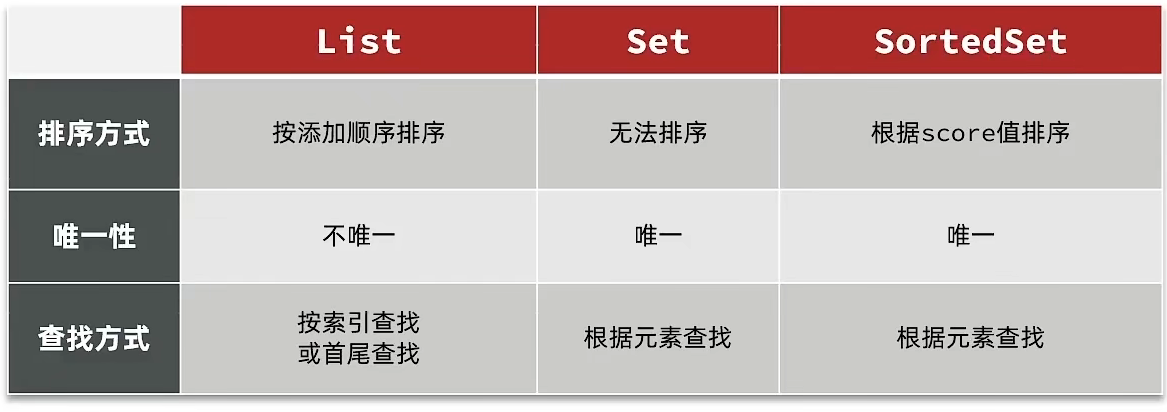
之前的点赞是放到set集合,但是set集合是不能排序的,所以这个时候,咱们可以采用一个可以排序的set集合,就是咱们的sortedSet
我们接下来来对比一下这些集合的区别是什么
所有点赞的人,需要是唯一的,所以我们应当使用set或者是sortedSet
其次我们需要排序,就可以直接锁定使用sortedSet啦
修改代码
BlogServiceImpl
点赞逻辑代码
1 |
|
点赞列表查询列表
BlogController
1 |
|
BlogService
1 |
|
9、好友关注
9.1 好友关注-关注和取消关注
针对用户的操作:可以对用户进行关注和取消关注功能。
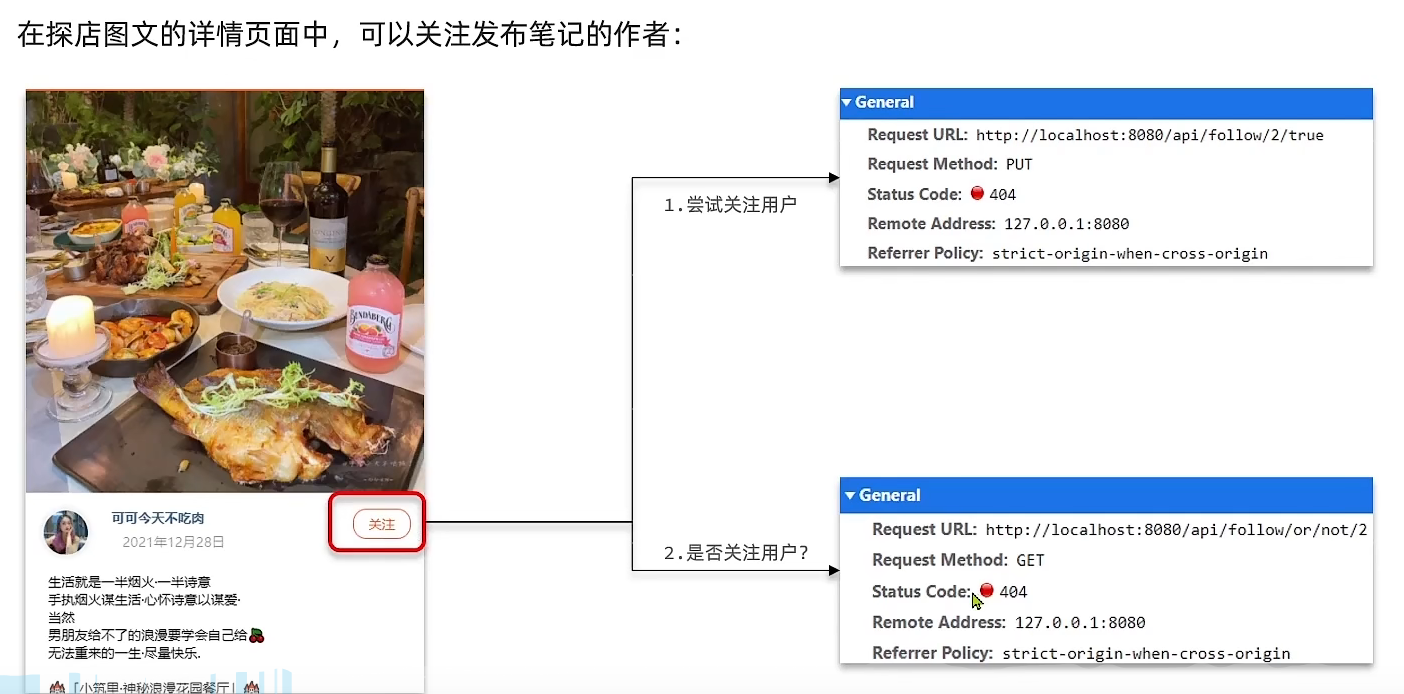
实现思路:
需求:基于该表数据结构,实现两个接口:
- 关注和取关接口
- 判断是否关注的接口
关注是User之间的关系,是博主与粉丝的关系,数据库中有一张tb_follow表来标示:
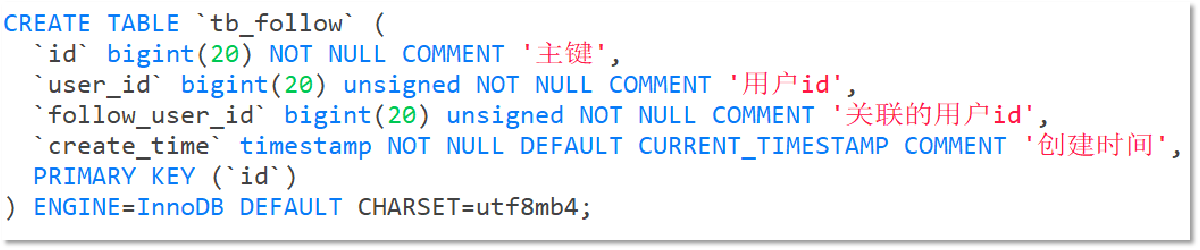
注意: 这里需要把主键修改为自增长,简化开发。
FollowController
1 | //关注 |
FollowService
1 | 取消关注service |
9.2 好友关注-共同关注
想要去看共同关注的好友,需要首先进入到这个页面,这个页面会发起两个请求
1、去查询用户的详情
2、去查询用户的笔记
以上两个功能和共同关注没有什么关系,大家可以自行将笔记中的代码拷贝到idea中就可以实现这两个功能了,我们的重点在于共同关注功能。
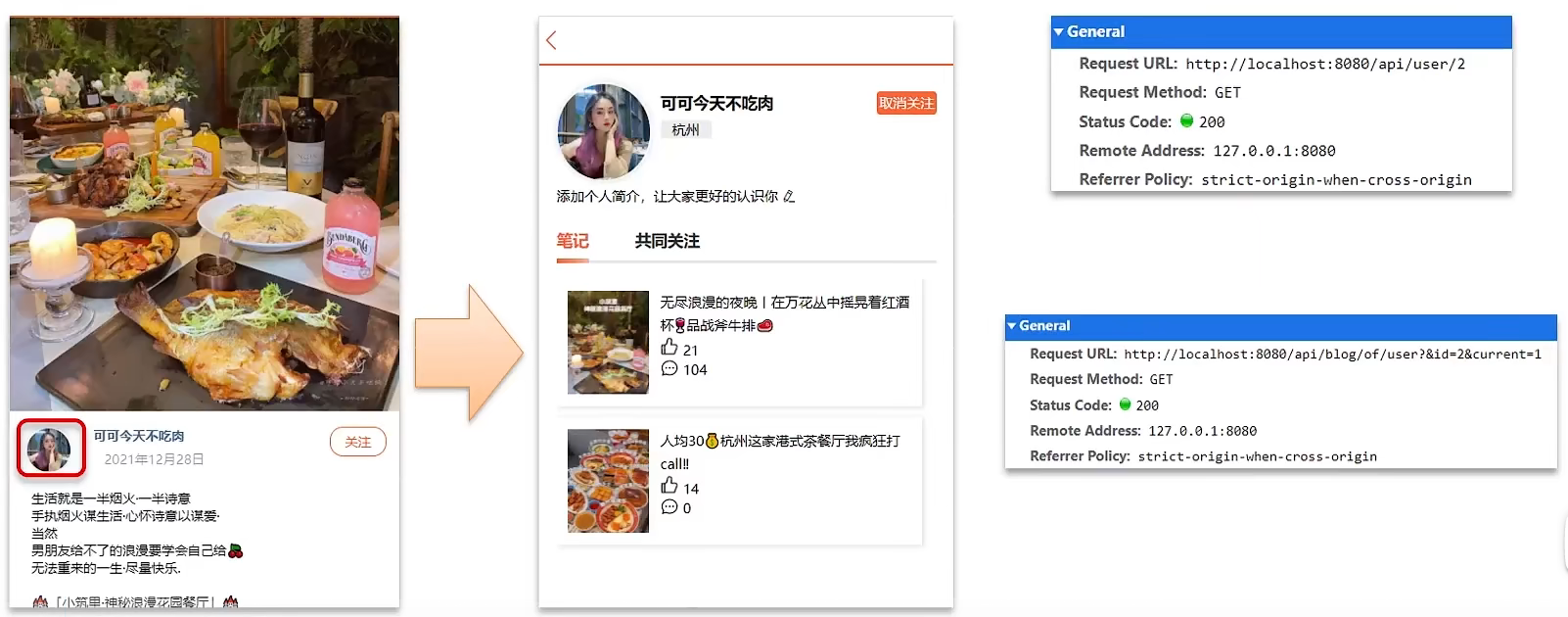
1 | // UserController 根据id查询用户 |
接下来我们来看看共同关注如何实现:
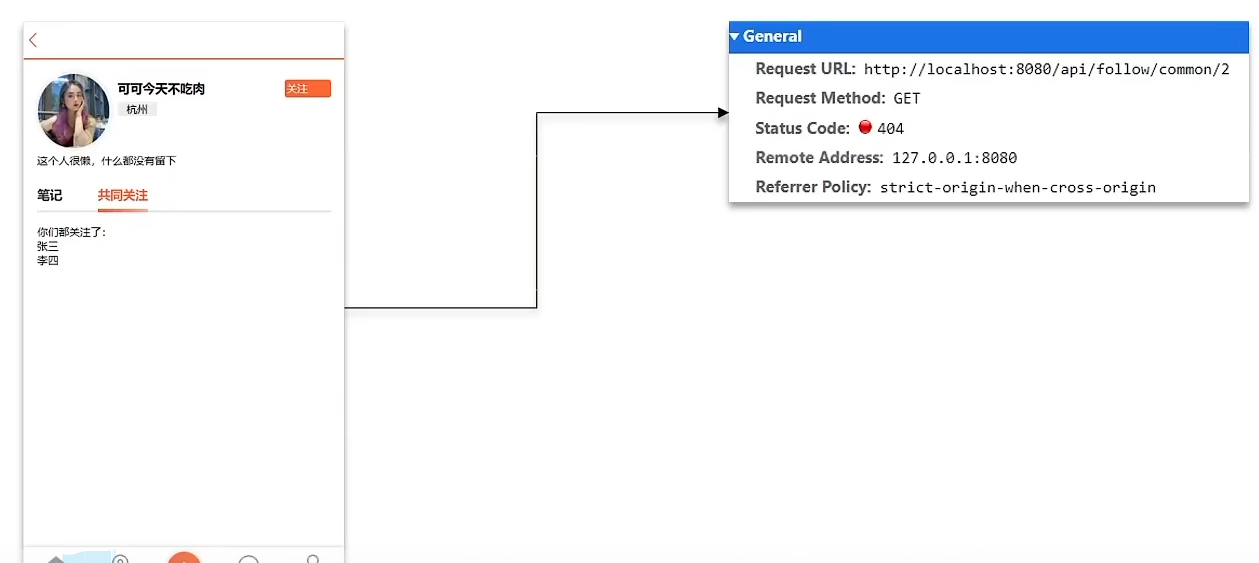
需求:利用Redis中恰当的数据结构,实现共同关注功能。在博主个人页面展示出当前用户与博主的共同关注呢。
当然是使用我们之前学习过的set集合咯,在set集合中,有交集并集补集的api,我们可以把两人的关注的人分别放入到一个set集合中,然后再通过api去查看这两个set集合中的交集数据。
我们先来改造当前的关注列表
改造原因是因为我们需要在用户关注了某位用户后,需要将数据放入到set集合中,方便后续进行共同关注,同时当取消关注时,也需要从set集合中进行删除
FollowServiceImpl
1 |
|
具体的关注代码:
FollowServiceImpl
1 |
|
9.3 好友关注-Feed流实现方案
当我们关注了用户后,这个用户发了动态,那么我们应该把这些数据推送给用户,这个需求,其实我们又把他叫做Feed流,关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
对于传统的模式的内容解锁:我们是需要用户去通过搜索引擎或者是其他的方式去解锁想要看的内容

对于新型的Feed流的的效果:不需要我们用户再去推送信息,而是系统分析用户到底想要什么,然后直接把内容推送给用户,从而使用户能够更加的节约时间,不用主动去寻找。

Feed流的实现有两种模式:
Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
我们本次针对好友的操作,采用的就是Timeline的方式,只需要拿到我们关注用户的信息,然后按照时间排序即可
,因此采用Timeline的模式。该模式的实现方案有三种:
- 拉模式
- 推模式
- 推拉结合
拉模式:也叫做读扩散
该模式的核心含义就是:当张三和李四和王五发了消息后,都会保存在自己的邮箱中,假设赵六要读取信息,那么他会从读取他自己的收件箱,此时系统会从他关注的人群中,把他关注人的信息全部都进行拉取,然后在进行排序
优点:比较节约空间,因为赵六在读信息时,并没有重复读取,而且读取完之后可以把他的收件箱进行清楚。
缺点:比较延迟,当用户读取数据时才去关注的人里边去读取数据,假设用户关注了大量的用户,那么此时就会拉取海量的内容,对服务器压力巨大。
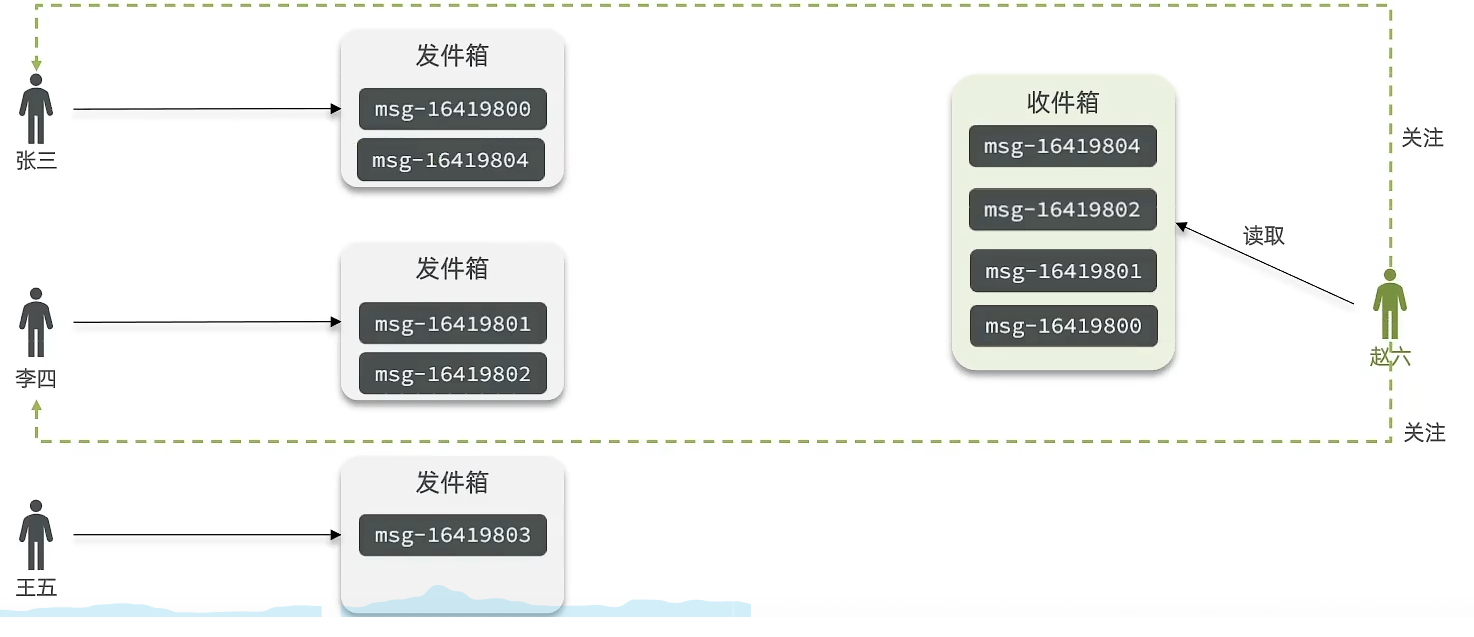
推模式:也叫做写扩散。
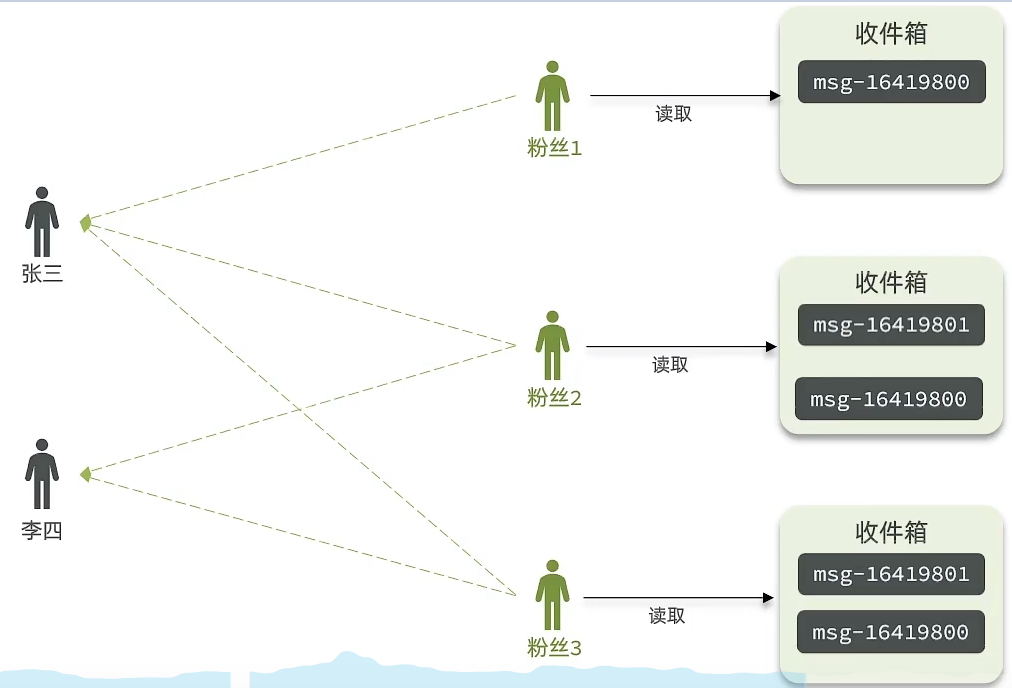
推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了
优点:时效快,不用临时拉取
缺点:内存压力大,假设一个大V写信息,很多人关注他, 就会写很多分数据到粉丝那边去
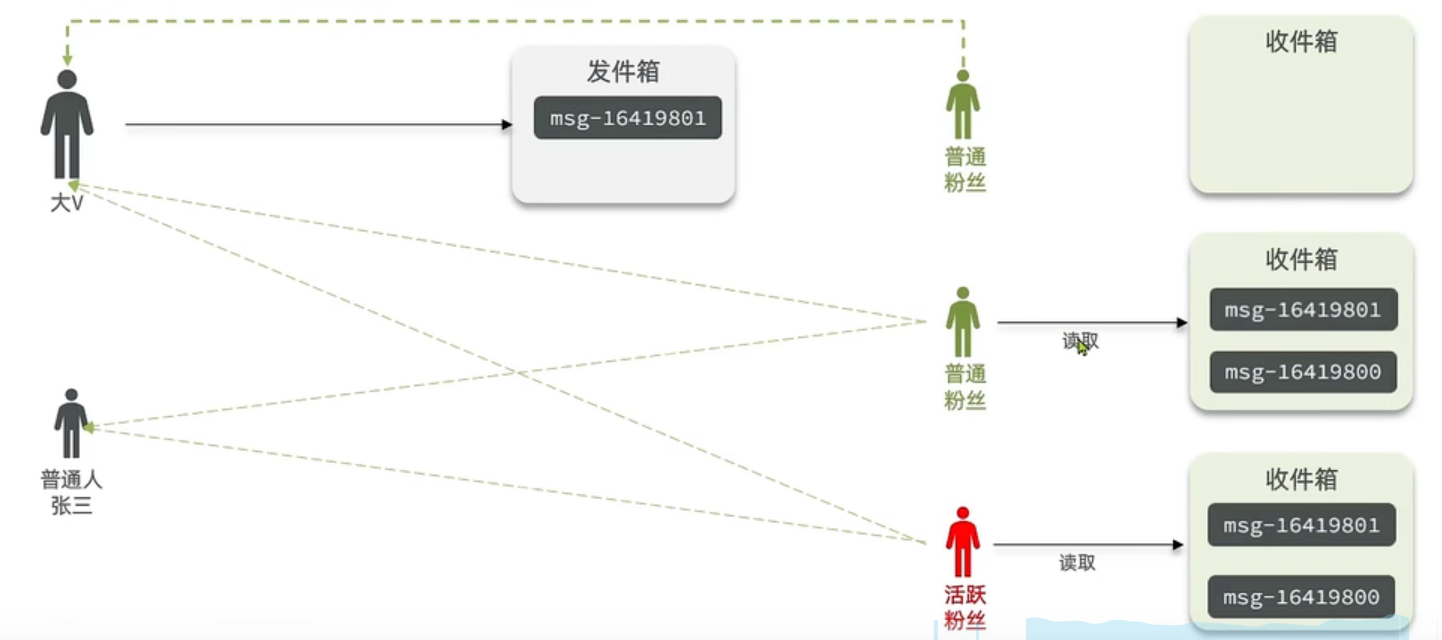
推拉结合模式:也叫做读写混合,兼具推和拉两种模式的优点。
推拉模式是一个折中的方案,站在发件人这一段,如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到他的粉丝中去,因为普通的人他的粉丝关注量比较小,所以这样做没有压力,如果是大V,那么他是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去,现在站在收件人这端来看,如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来,而如果是普通的粉丝,由于他们上线不是很频繁,所以等他们上线时,再从发件箱里边去拉信息。
9.4 好友关注-推送到粉丝收件箱
需求:
- 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
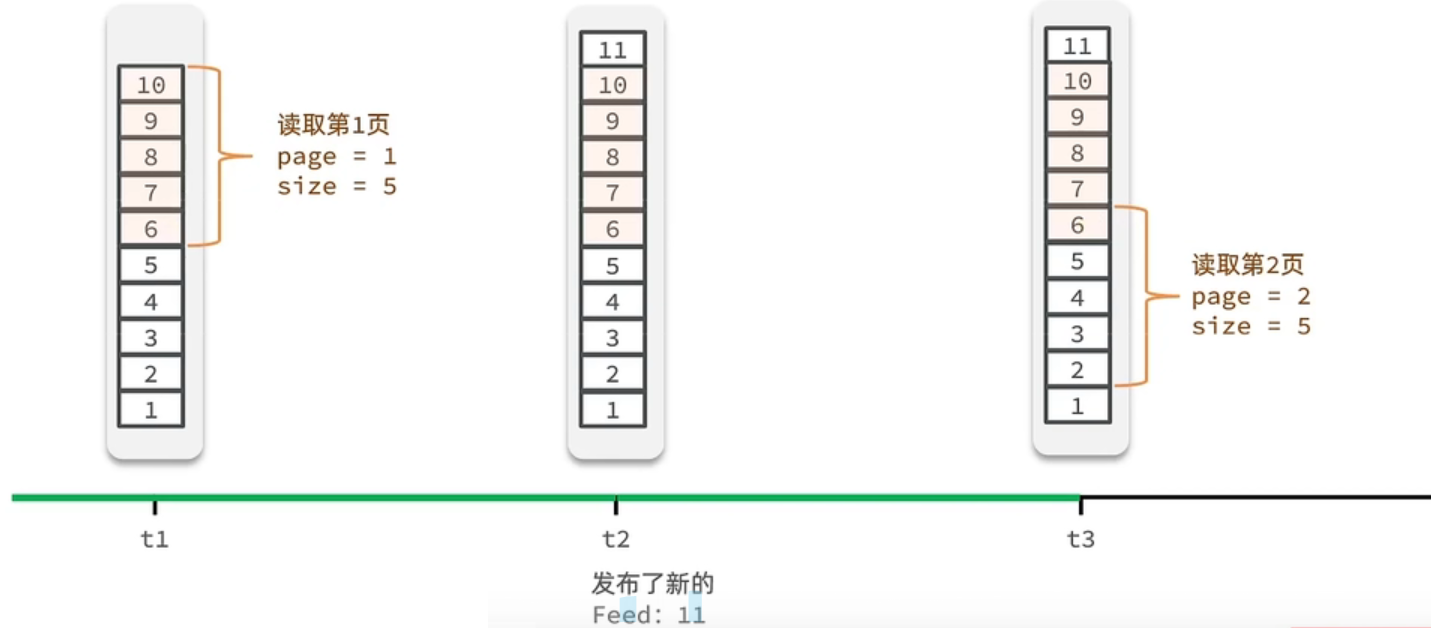
Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。
传统了分页在feed流是不适用的,因为我们的数据会随时发生变化
假设在t1 时刻,我们去读取第一页,此时page = 1 ,size = 5 ,那么我们拿到的就是106 这几条记录,假设现在t2时候又发布了一条记录,此时t3 时刻,我们来读取第二页,读取第二页传入的参数是page=2 ,size=5 ,那么此时读取到的第二页实际上是从6 开始,然后是62 ,那么我们就读取到了重复的数据,所以feed流的分页,不能采用原始方案来做。
Feed流的滚动分页
我们需要记录每次操作的最后一条,然后从这个位置开始去读取数据
举个例子:我们从t1时刻开始,拿第一页数据,拿到了10~6,然后记录下当前最后一次拿取的记录,就是6,t2时刻发布了新的记录,此时这个11放到最顶上,但是不会影响我们之前记录的6,此时t3时刻来拿第二页,第二页这个时候拿数据,还是从6后一点的5去拿,就拿到了5-1的记录。我们这个地方可以采用sortedSet来做,可以进行范围查询,并且还可以记录当前获取数据时间戳最小值,就可以实现滚动分页了
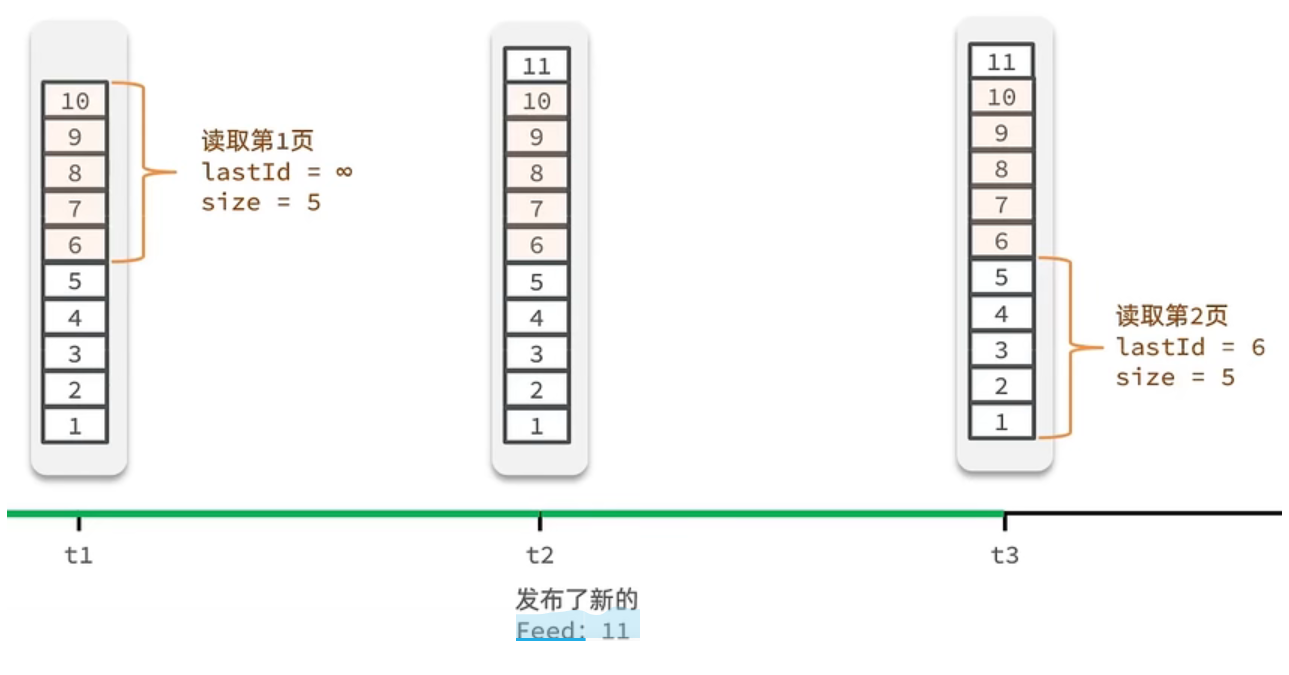
核心的意思:就是我们在保存完探店笔记后,获得到当前笔记的粉丝,然后把数据推送到粉丝的redis中去。
1 |
|
9.5好友关注-实现分页查询收邮箱
需求:在个人主页的“关注”卡片中,查询并展示推送的Blog信息:
具体操作如下:
1、每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件
2、我们需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
综上:我们的请求参数中就需要携带 lastId:上一次查询的最小时间戳 和偏移量这两个参数。
这两个参数第一次会由前端来指定,以后的查询就根据后台结果作为条件,再次传递到后台。

一、定义出来具体的返回值实体类
1 |
|
BlogController
注意:RequestParam 表示接受url地址栏传参的注解,当方法上参数的名称和url地址栏不相同时,可以通过RequestParam 来进行指定
1 |
|
BlogServiceImpl
1 |
|
10、附近商户
10.1、附近商户-GEO数据结构的基本用法
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
10.2、 附近商户-导入店铺数据到GEO
具体场景说明:
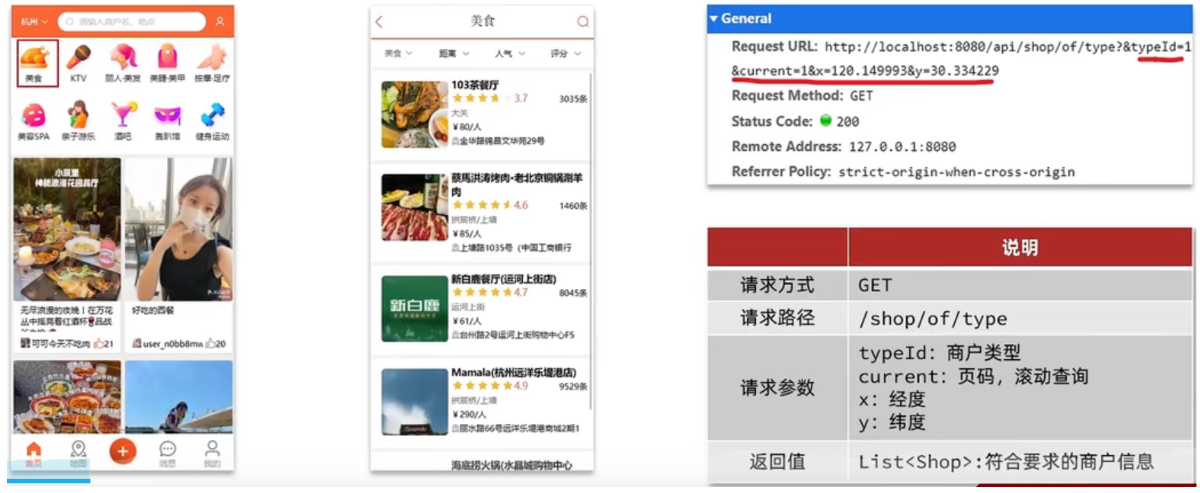
当我们点击美食之后,会出现一系列的商家,商家中可以按照多种排序方式,我们此时关注的是距离,这个地方就需要使用到我们的GEO,向后台传入当前app收集的地址(我们此处是写死的) ,以当前坐标作为圆心,同时绑定相同的店家类型type,以及分页信息,把这几个条件传入后台,后台查询出对应的数据再返回。
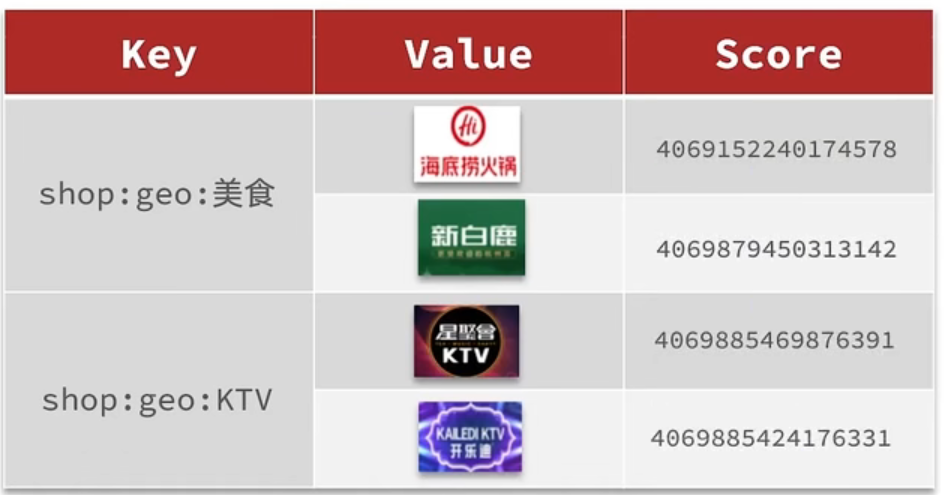
我们要做的事情是:将数据库表中的数据导入到redis中去,redis中的GEO,GEO在redis中就一个menber和一个经纬度,我们把x和y轴传入到redis做的经纬度位置去,但我们不能把所有的数据都放入到menber中去,毕竟作为redis是一个内存级数据库,如果存海量数据,redis还是力不从心,所以我们在这个地方存储他的id即可。
但是这个时候还有一个问题,就是在redis中并没有存储type,所以我们无法根据type来对数据进行筛选,所以我们可以按照商户类型做分组,类型相同的商户作为同一组,以typeId为key存入同一个GEO集合中即可
代码
HmDianPingApplicationTests
1 |
|
10.3 附近商户-实现附近商户功能
SpringDataRedis的2.3.9版本并不支持Redis 6.2提供的GEOSEARCH命令,因此我们需要提示其版本,修改自己的POM
第一步:导入pom
1 | <dependency> |
第二步:
ShopController
1 |
|
ShopServiceImpl
1 |
|
11、用户签到
11.1、用户签到-BitMap功能演示
我们针对签到功能完全可以通过mysql来完成,比如说以下这张表
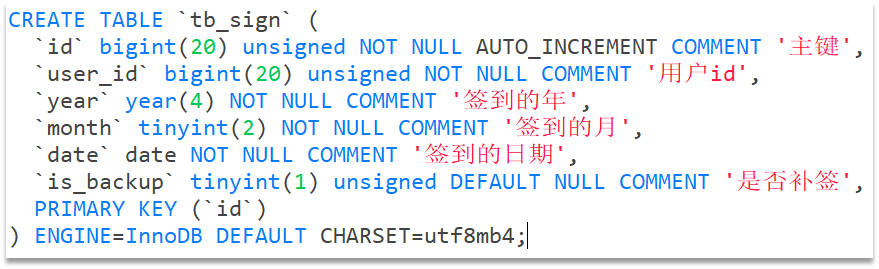
用户一次签到,就是一条记录,假如有1000万用户,平均每人每年签到次数为10次,则这张表一年的数据量为 1亿条
每签到一次需要使用(8 + 8 + 1 + 1 + 3 + 1)共22 字节的内存,一个月则最多需要600多字节
我们如何能够简化一点呢?其实可以考虑小时候一个挺常见的方案,就是小时候,咱们准备一张小小的卡片,你只要签到就打上一个勾,我最后判断你是否签到,其实只需要到小卡片上看一看就知道了
我们可以采用类似这样的方案来实现我们的签到需求。
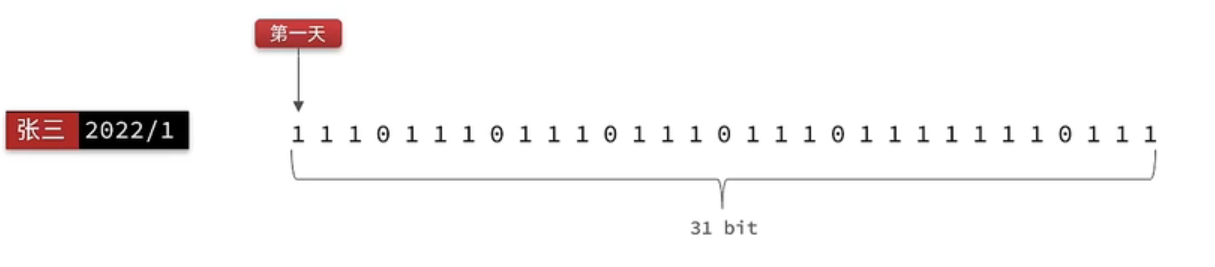
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0.
把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。这样我们就用极小的空间,来实现了大量数据的表示
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是 2^32个bit位。
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一个0或1
- GETBIT :获取指定位置(offset)的bit值
- BITCOUNT :统计BitMap中值为1的bit位的数量
- BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
- BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
11.2 、用户签到-实现签到功能
需求:实现签到接口,将当前用户当天签到信息保存到Redis中
思路:我们可以把年和月作为bitMap的key,然后保存到一个bitMap中,每次签到就到对应的位上把数字从0变成1,只要对应是1,就表明说明这一天已经签到了,反之则没有签到。
我们通过接口文档发现,此接口并没有传递任何的参数,没有参数怎么确实是哪一天签到呢?这个很容易,可以通过后台代码直接获取即可,然后到对应的地址上去修改bitMap。

代码
UserController
1 |
|
UserServiceImpl
1 |
|
11.3 用户签到-签到统计
**问题1:**什么叫做连续签到天数?
从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。

Java逻辑代码:获得当前这个月的最后一次签到数据,定义一个计数器,然后不停的向前统计,直到获得第一个非0的数字即可,每得到一个非0的数字计数器+1,直到遍历完所有的数据,就可以获得当前月的签到总天数了
**问题2:**如何得到本月到今天为止的所有签到数据?
BITFIELD key GET u[dayOfMonth] 0
假设今天是10号,那么我们就可以从当前月的第一天开始,获得到当前这一天的位数,是10号,那么就是10位,去拿这段时间的数据,就能拿到所有的数据了,那么这10天里边签到了多少次呢?统计有多少个1即可。
问题3:如何从后向前遍历每个bit位?
注意:bitMap返回的数据是10进制,哪假如说返回一个数字8,那么我哪儿知道到底哪些是0,哪些是1呢?我们只需要让得到的10进制数字和1做与运算就可以了,因为1只有遇见1 才是1,其他数字都是0 ,我们把签到结果和1进行与操作,每与一次,就把签到结果向右移动一位,依次内推,我们就能完成逐个遍历的效果了。
需求:实现下面接口,统计当前用户截止当前时间在本月的连续签到天数
有用户有时间我们就可以组织出对应的key,此时就能找到这个用户截止这天的所有签到记录,再根据这套算法,就能统计出来他连续签到的次数了

代码
UserController
1 |
|
UserServiceImpl
1 |
|
11.4 额外加餐-关于使用bitmap来解决缓存穿透的方案
回顾缓存穿透:
发起了一个数据库不存在的,redis里边也不存在的数据,通常你可以把他看成一个攻击
解决方案:
- 判断id<0
- 如果数据库是空,那么就可以直接往redis里边把这个空数据缓存起来
第一种解决方案:遇到的问题是如果用户访问的是id不存在的数据,则此时就无法生效
第二种解决方案:遇到的问题是:如果是不同的id那就可以防止下次过来直击数据
所以我们如何解决呢?
我们可以将数据库的数据,所对应的id写入到一个list集合中,当用户过来访问的时候,我们直接去判断list中是否包含当前的要查询的数据,如果说用户要查询的id数据并不在list集合中,则直接返回,如果list中包含对应查询的id数据,则说明不是一次缓存穿透数据,则直接放行。
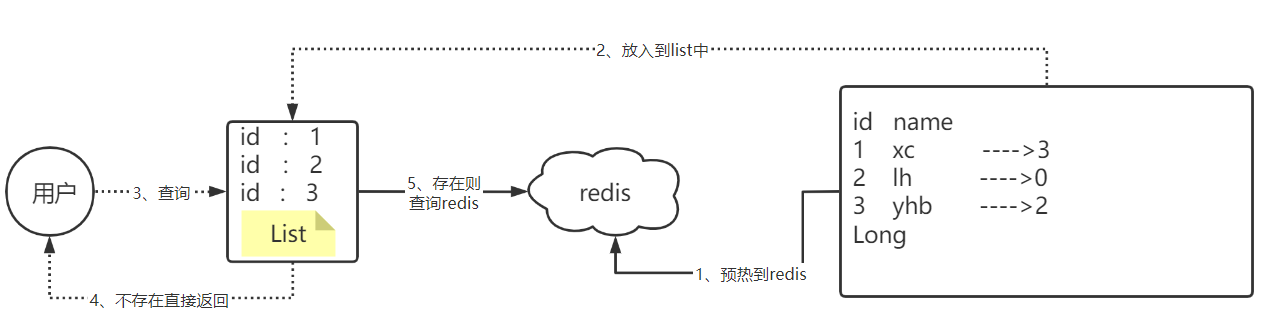
现在的问题是这个主键其实并没有那么短,而是很长的一个 主键
哪怕你单独去提取这个主键,但是在11年左右,淘宝的商品总量就已经超过10亿个
所以如果采用以上方案,这个list也会很大,所以我们可以使用bitmap来减少list的存储空间
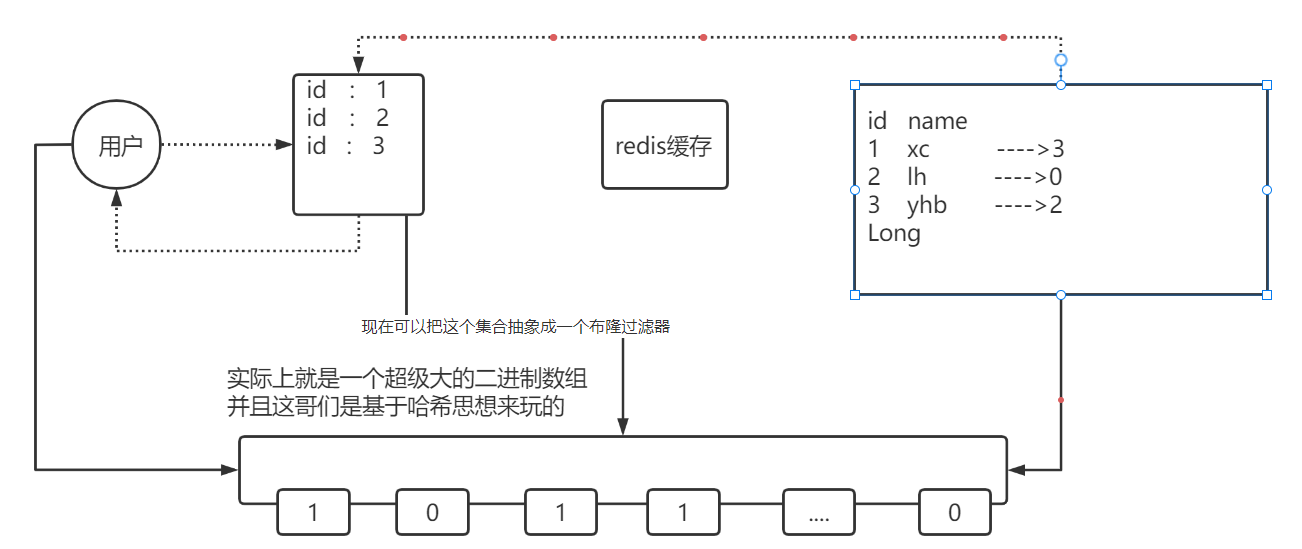
我们可以把list数据抽象成一个非常大的bitmap,我们不再使用list,而是将db中的id数据利用哈希思想,比如:
id % bitmap.size = 算出当前这个id对应应该落在bitmap的哪个索引上,然后将这个值从0变成1,然后当用户来查询数据时,此时已经没有了list,让用户用他查询的id去用相同的哈希算法, 算出来当前这个id应当落在bitmap的哪一位,然后判断这一位是0,还是1,如果是0则表明这一位上的数据一定不存在, 采用这种方式来处理,需要重点考虑一个事情,就是误差率,所谓的误差率就是指当发生哈希冲突的时候,产生的误差。
12、UV统计
12.1 、UV统计-HyperLogLog
首先我们搞懂两个概念:
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
通常来说UV会比PV大很多,所以衡量同一个网站的访问量,我们需要综合考虑很多因素,所以我们只是单纯的把这两个值作为一个参考值
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖,那怎么处理呢?
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
12.2 UV统计-测试百万数据的统计
测试思路:我们直接利用单元测试,向HyperLogLog中添加100万条数据,看看内存占用和统计效果如何
1 |
|
经过测试:我们会发生他的误差是在允许范围内,并且内存占用极小
完结撒花!!!(后面的高级和原理篇暂时不打算做笔记了,要提速了)


